

In my previous post on AI engineering I defined the concepts involved in this new discipline and explained that with the current state of the practice, AI engineers could also be named machine learning (ML) engineers. Burkov (2020) defines ML engineering as a mix between “scientific principles, tools, and techniques of machine learning and traditional software engineering to design and build complex computing systems”. Karnowski and Fadely (2016) describe the rise of three new AI roles: AI professional, data engineer en data scientist. In their definition the AI professional needs knowledge of machine learning, software engineering and data. At Fontys Applied University we educate professional (bachelor-level) software engineers with a specialization in machine learning. These AI engineers need to be able to build software systems that contain a machine learning component by making use of existing machine learning models. This could be through APIs, through machine learning libraries, through autoML solutions, by using model code from open source repositories, or by implementing a model in code that has been designed by a data scientist. In this post I would like to 1) define our view on the profession of applied AI engineer and 2) present the toolbox of an AI engineer with tools, methods and techniques to defy the challenges AI engineers typically face. I end this post with a short overview of related work and future directions. Attached to it is an extensive list of references and additional reading material.
The Applied AI Engineer
Stichting HBO-i (the Dutch nationwide network of all applied universities for IT-education) defines the applied AI engineer as an (embedded) software engineer that incorporates machine learning components in software or hardware. According to them the applied AI engineer elicitates data and software requirements, processes data to be able to apply ML, trains ML models and incorporates trained models in (embedded) software systems. This corresponds with the ML cycle as depicted by Farah (2020):
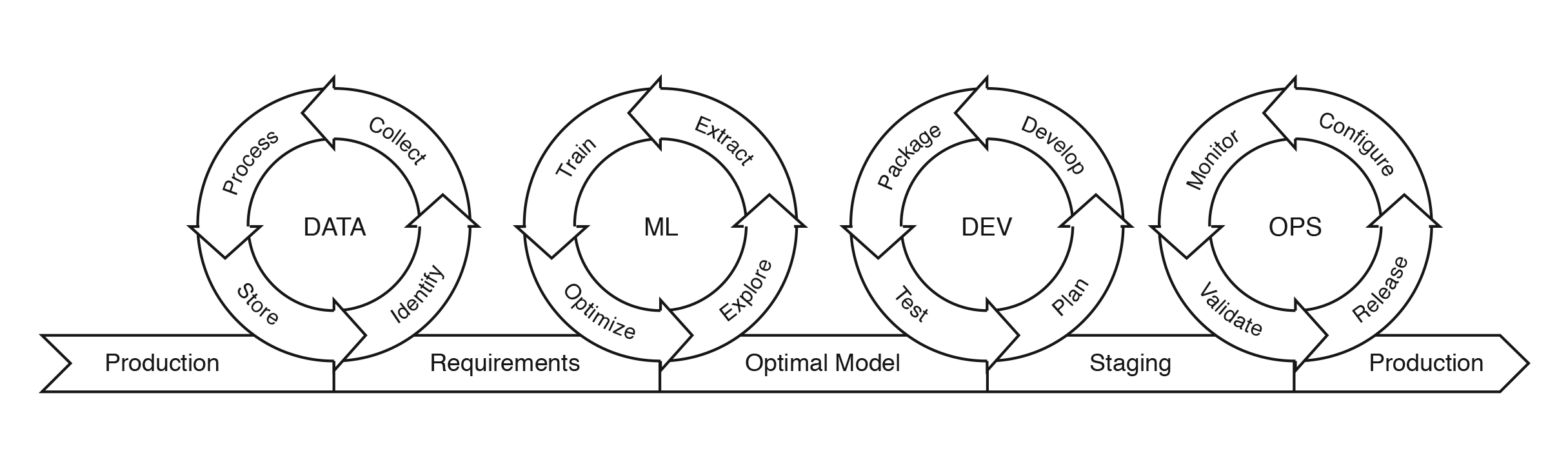
Fig 1. ML cycle, adapted from Farah (2020)
The applied AI engineer needs to have knowledge and basic skills of all of the steps in figure 1, and should excel in one of the four areas involved: data processing, machine learning, software engineering or IT operations. For the other three areas it is important to be able to work together with others that excel in those areas: data engineers, data scientists/analysts, software engineers and IT operation engineers.
At Fontys Applied University we educate applied AI engineers that excel in software engineering and we offer them an AI specialization of 2 semesters (60 ects) that focuses on data analysis and machine learning:
- IBM Data Science Methodology (Rollins, 2015), based on CRISP-DM (Chapman et al., 2000), as a project apporach for ML projects
- Data quality: a) data cleaning, b) handling missing data, c) reporting
- Feature engineering
- Basic statistics (mean, median, standard deviation, etc.)
- Basic machine learning algorithms: a) regression, b) tree-based methods, c) SVMs, d) neural networks
- Modelling techniques: a) cross-validation, b) model performance evaluation metrics, c) dimensionality reduction
- Exploratory data visualisation with matplotlib
- Data visualisation: a) basic charts; b) advanced analytics; c) visual design principles; d) Info-graphics; e) interactive visualisations
- Writing a business proposal for an AI project
- Ethical and legal aspects of AI projects
- Organisational context: explaining the importance of data-driven maturity of an organisation when applying machine learning
- Societal context: a) smart cities; b) sustainable development goals
- Setting up a cloud environment: a) data sources; b) web scraping; c) cloud tools/APIs
- Advanced machine learning algorithms: a) CNNs, b) RNNs, c) reinforcement learning
- Natural Language Processing (NLP)
We teach our students how to apply and evaluate a number of standard AI algorithms, focusing on the main concepts behind machine learning. Each semester is based on a real project from an external client, so we also pay attention to the business understanding and societal impact of AI projects. The 4 semesters of software engineering the students follow, give them basic knowledge on data engineering and DevOps (the IT operations part of AI engineering) so they usually figure out that part of the project by themselves, but we also hand them MLOps tools like DVC and MLFlow to manage their AI projects.
As far as programming AI goes, we use Python and Tensorflow for our teacher material and we show them the power of Tableau for interactive data visualization.
The AI Engineering Toolbox
In my previous post I argued that AI or ML engineering is different from traditional (rule-based) software engineering. I identified eight challenges for AI engineers (assuming they have been educated as traditional software engineer):
- [CH1] Data requirements engineering including data visualizations
- [CH2] ML components are more difficult to handle as distinct modules
- [CH3a] Design of the ML component through algorithm selection and tuning
- [CH3b] Break up the ML development in increments
- [CH4a] Data and model management for the current and future projects
- [CH4b] Find ML models that can be reused for your application
- [CH5a] Validation of ML applications in absence of a specification to test against
- [CH5b] Explainability of ML models is needed for debugging
In this post I describe a number of tools/techniques/methods that should be in each AI engineers toolbox to address those challenges. Next to that the toolbox should of course also be filled with the regular tools/techniques/methods from software engineering or data science (depending on the background or specialization of the AI engineer). In the following I discuss hands-on solutions for each of the 8 challenges, where I regrouped them into 5 sections, CH1 till CH5 above. Each solution offers a list of references to other sources. For a more detailed description of the solutions, see my book chapter “A Software Engineering Perspective on Building Production-Ready Machine Learning Systems” (with Gerard Schouten en Luís Cruz).
[CH1] Elicitation of Data and Model Requirements
For an ML system, data, model, and software requirements should be elicitated. In this section I present two approaches from software engineering (domain modeling and requirements engineering) and three approaches from data science (exploratory data analysis, data quality check, data visualization) for that elicitation.
Domain Modeling
- Entity-Relationship (ER) modeling (Thalheim, 2013)
- Analytics Canvas (Kühn et al., 2018)
- “Data-Analytic Thinking” (Provost and Fawcett, 2013)
Requirements Engineering
- Requirements engineering (Bourque & Fairley, 2014)
- A systematic approach to requirements engineering (Sommerville and Sawyer, 1997)
Exploratory Data Analysis
- Exploratory Data Analysis (Alspaugh et al., 2018)
- Literate programming tools (Kery et al., 2018)
Data Quality Check
- Best practices to avoid common problems with data (Burkov 2020)
- Testing data (Heck, 2020)
Data Visualization
- The Handbook of Data Visualization (Chen et al., 2007)
- Tools for data visualization (Alspaugh et al., 2018)
- Visual Analytics (Keim et al., 2010)
[CH2] Modularizing the Application
Software engineering provides several approaches to design high-quality applications, including componentization, design patterns, pipelines, and containerization. These approaches also apply to ML system design. After defining high-quality requirements, a high-quality design is the next step toward building high-quality (production-ready) ML systems.
Componentizing ML Systems
Although individual ML models cannot be divided in smaller components, the ML system as a whole should be divided into components that each solve a smaller part of the large complex problem. E.g., first recognize a vehicle in the picture, than recognize the license plate on the vehicle and then try to read the numbers on the plate.
ML Design Patterns and Standards
- Architecture patterns, design patterns, and anti-patterns for ML application systems (Washizaki et al., 2020).
- Technical debt (Sculley et al., 2014) (McAteer, 2020)
- Architecture patterns for decomposing inference tasks (Pinhasi, 2020)
- Reference architecture of knowledge engineering (ISO/IEC JTC 1 SC42)
Pipelines
- “It is important to develop a ‘rock solid’ data pipeline capable of continuous loading and massaging data, enabling engineers to try out many permutations of AI algorithms with different hyper-parameter without hassle.” (Amershi et al., 2019)
- See for example pipelines in the Microsoft Azure Cloud environment (Microsoft, 2020a).
Containerization
- Containerizing intelligent applications (Benton, 2020)
- Kubeflow provides tooling to make ML scalable and repeatable on Kubernetes
[CH3] Design through Experimentation
The ML process is highly experimental and iterative by nature. Software engineering techniques and tools that deal with this uncertainty also transfer to an ML process (agile data science, development tools for experiments and AutoML). Each of these three solutions is detailed in the remainder of the section. An agile approach and automation lead to high-quality development processes that are needed to build high-quality (production-ready) ML systems.
Agile Data Science
- Agile data science (Jurney, 2017)
- Combining data science and agile (Yan, 2019)
- The Microsoft Team Data Science Process (Microsoft, 2020b)
- The engineering loop (Ameisen, 2018)
Development Tools for Experiments
- Literate programming tools, e.g., Polynote
- Libraries, e.g., PyCaret
- Platforms for experiment tracking and automation of the ML lifecycle, e.g., MLFlow and Comet
Automated ML (AutoML)
Wang et al. (2019) conclude that AutoML will augment the work of AI engineers, not replace it. Examples are: Google AutoML, H2O Driverless AI, and RapidMiner Auto Model.
[CH4] Data and Model Management
ML systems need to be traceable in data, model and code. Software engineering provides approaches for traceability and reuse of code that also translate to ML systems: version control, documentation, APIs, and libraries. Having traceable and properly documented artefacts is a prerequisite for putting an ML system into production, even more so for updating the ML system once it is in the production environment.
ML Version Control
- DVC
- Data stores, e.g. Azure ML Datasets
- Model stores, e.g. Azure ML Model Registry
- DSML (Data Science and ML) platforms like Dataiku and Databricks that include data and model version control as part of an integrated whole.
Data and Model Documentation
- Document each column of the dataset (Zinkevich, 2017)
- Model Cards (Mitchell et al., 2019)
- OSGi specification of ML model’s capabilities (Kriens and Verbelen, 2019)
Model APIs and Libraries
- Microsoft Cognitive Services (Raman & Hoder, 2020): vision, speech, language, decision, and web search.
- PoseNet (Oved, 2018): real-time human pose estimation
- OpenCV: real-time computer vision
[CH5] Testing
This section presents several approaches from software testing and how they translate to ML systems: testing ML systems, online testing, test set adequacy, test-driven ML, and testing for interpretability and fairness). Having a high-quality test approach is paramount to determine if the ML system is, in fact, production-ready, and for monitoring the quality of the ML system after deployment in the production environment.
Testing ML Systems
- AI and Software Testing Foundation Syllabus (Alliance for Qualification, 2019).
- Literature survey of 128 papers on testing ML ( Zhang et al., 2020)
- Practical engineering tools and best practices for testing ML systems (Heck, 2020)
- Coding standards or coding practices for ML code (Tan, 2019)
Online Testing and Monitoring
- An ML testing workflow should also contain online testing activities to complement the shortage of offline testing (J. Zhang et al., 2020).
- Monitor user behavior in response to different model versions, e.g. using A/B testing or multi-armed bandit (Burkov, 2020).
- Continuous monitoring of the production model(s) (Burkov, 2020)
- “know how to craft experiences that collect the data needed to evaluate and grow intelligence.” (Hulten, 2019)
Test Set Adequacy
- Neuron coverage (Burkov, 2020) and other coverage notions for deep neural networks ( Zhang et al., 2020)
- ML Test Score (Breck et al., 2016)
Test-Driven ML
Bozonier (2015) and Kirk (2017) provide detailed examples in their books that help practitioners adopt test-driven ML.
Testing for Interpretability and Fairness
- Explainable Artificial Intelligence (XAI) (Adadi and Berrada, 2018)
- Book “Interpretable ML”, with examples in R (Molnar, 2020)
- Explainability toolkit XAI, available for Python
- InterpretML, a Python package (Nori et al., 2019)
- Fairness for ML, including a few test generation techniques for fairness testing ( Zhang et al., 2020)
- IBM AI Fairness 360 Open Source Toolkit, including AI Fairness 360 Python package (Bellamy et al., 2019)
- Microsoft FairLearn toolkit, a Python package (Bird et al., 2020)
- Ethical AI (Floridi & Cowls, 2019)
- Ethical System Development Lifecycle E-SDLC (Spiekermann, 2015)
- Technology Impact Cycle Tool
Related Work
While collecting the toolbox contents, I ran into a number of papers/books/blogs that describe AI engineering (sometimes called ML engineering) from a broader perspective. This section sums up this related work per topic:
- Software engineering for machine learning (Marbán et al., 2009) (Hesenius et al., 2019) (Ozkaya, 2020)
- Challenges for building ML systems (Amershi et al., 2019) (Belani et al., 2019) (Lwakatare et al., 2019) (Lwakatare et al., 2020) (Arpteg et al., 2018) (Ishikawa and Yoshioka, 2019) (Kim et al., 2017) ( Zhang et al., 2019)
- Best practices for building ML systems (Amershi et al., 2019) (Kim et al., 2017) (Lwakatare et al., 2020) (De Souza Nascimento et al., 2019) (Zinkevich, 2017) (Serban et al., 2020)
Future Directions
To conclude this post I present some future developments I found.
Industry Trends
- Cloud AI Developer Services (Baker et al., 2020)
- ML-capabilities in low-code platforms like Mendix and Appian and Robotic Process Automation (RPA) tools like UIPath and Automation Anywhere
- According to Karnowski and Fadely (2016), a new role is emerging: the AI professional (Heck & Schouten, 2021; Menzies, 2019).
Research Directions
- Development process models for ML engineering to incorporate data scientists (Ozkaya, 2020)
- Assuring the ML lifecycle for safety-critical systems (Ashmore et al., 2019)
- Research agenda for AI engineering (Bosch et al., 2020)
Conclusion
AI engineering has only recently emerged as a new discipline, so the toolbox discussed in this chapter is volatile. Through research, case studies and our experience in educating AI engineers we will keep updating our AI engineer’s toolbox.
References
Abbasi-Sureshjani, S., Raumanns, R., Michels, B. E. J., Schouten, G., & Cheplygina, V. (2020). Risk of training diagnostic algorithms on data with demographic bias. Lecture Notes in Computer Science, 12446, 183-192.
Adadi, A., & Berrada, M. (2018). Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI). IEEE Access, 6, 52138-52160.
Akkiraju, R., Sinha, V., Xu, A., Mahmud, J., Gundecha, P., Liu, Z., Liu, X., & Schumacher, J. (2020). Characterizing machine learning processes: A maturity framework. Paper presented at the International Conference on Business Process Management.
Algorithmia. (2020). The roadmap to machine learning maturity. Retrieved from https://info.algorithmia.com/hubfs/2018/Whitepapers/The_Roadmap_to_Machine_Learning_Maturity_Final.pdf
Alliance for Qualification. (2019). AI and Software Testing Foundation Syllabus. Retrieved from https://www.alliance4qualification.info/a4q-ai-and-software-testing
Alspaugh, S., Zokaei, N., Liu, A., Jin, C., & Hearst, M. A. (2018). Futzing and moseying: Interviews with professional data analysts on exploration practices. IEEE transactions on visualization and computer graphics, 25(1), 22-31.
Ameisen, E. (2018). How to deliver on Machine Learning projects. A guide to the ML Engineering Loop. Retrieved from https://blog.insightdatascience.com/how-to-deliver-on-machine-learning-projects-c8d82ce642b0
Amershi, S., Begel, A., Bird, C., DeLine, R., Gall, H., Kamar, E., Nagappan, N., Nushi, B., & Zimmermann, T. (2019). Software engineering for machine learning: A case study. Paper presented at the 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP).
Arpteg, A., Brinne, B., Crnkovic-Friis, L., & Bosch, J. (2018). Software engineering challenges of deep learning. Paper presented at the 2018 44th Euromicro Conference on Software Engineering and Advanced Applications (SEAA).
Ashmore, R., Calinescu, R., & Paterson, C. (2019). Assuring the machine learning lifecycle: Desiderata, methods, and challenges. arXiv preprint arXiv:1905.04223.
Bailis, P., Olukotun, K., Ré, C., & Zaharia, M. (2017). Infrastructure for usable machine learning: The stanford dawn project. arXiv preprint arXiv:1705.07538.
Baker, V., Elliot, B., Sicular, S., Mullen, A., & Brethenoux, E. (2020). Magic quadrant for cloud AI developer services. Retrieved from https://www.gartner.com/en/documents/3981253/magic-quadrant-for-cloud-ai-developer-services
Belani, H., Vukovic, M., & Car, Ž. (2019). Requirements engineering challenges in building AI-based complex systems. Paper presented at the 2019 IEEE 27th International Requirements Engineering Conference Workshops (REW).
Bellamy, R. K., Dey, K., Hind, M., Hoffman, S. C., Houde, S., Kannan, K., Lohia, P., Martino, J., Mehta, S., & Mojsilović, A. (2019). AI Fairness 360: An extensible toolkit for detecting and mitigating algorithmic bias. IBM Journal of Research and Development, 63(4/5), 4: 1-4: 15.
Benton, W. C. (2020). Machine learning systems and intelligent applications. IEEE Software, 37(04).
Bird, S., Dudík, M., Edgar, R., Horn, B., Lutz, R., Milan, V., Sameki, M., Wallach, H., & Walker, K. (2020). Fairlearn: A toolkit for assessing and improving fairness in AI. Retrieved from https://www.microsoft.com/en-us/research/uploads/prod/2020/05/Fairlearn_WhitePaper-2020-09-22.pdf
Bosch, J., Crnkovic, I., & Olsson, H. H. (2020). Engineering AI systems: A research agenda. arXiv preprint arXiv:2001.07522.
Bourque, P., & Fairley, R. (2014). Guide to the software engineering body of knowledge (SWEBOK (R)): Version 3.0. IEEE Computer Society Press.
Bozonier, J. (2015). Test-driven machine learning. Packt Publishing Ltd.
Breck, E., Cai, S., Nielsen, E., Salib, M., & Sculley, D. (2016). What’s your ML Test Score? A rubric for ML production systems. Paper presented at the Reliable Machine Learning in the Wild – NIPS 2016 Workshop.
Breuel, C. (2020, Jan 3, 2020). MLOps: Machine learning as an engineering discipline. Retrieved from https://towardsdatascience.com/ml-ops-machine-learning-as-an-engineering-discipline-b86ca4874a3f
Burkov, A. (2020). Machine learning engineering. True Positive Inc.
Cai, S., Bileschi, S., Nielsen, E. D., & Chollet, F. (2020). Deep learning with JavaScript. Manning.
Chapman, P., Clinton, J., Kerber, R., Khabaza, T., Reinartz, T., Shearer, C., & Wirth, R. (2000). CRISP-DM 1.0: Step-by-step data mining guide.
Chen, C., Härdle, W. K., & Unwin, A. (2007). Handbook of data visualization. Springer Science & Business Media.
Cliffydcw (Producer). (2020). Own work. Retrieved from https://commons.wikimedia.org/w/index.php?curid=19054763
De Souza Nascimento, E., Ahmed, I., Oliveira, E., Palheta, M. P., Steinmacher, I., & Conte, T. (2019). Understanding development process of machine learning systems: Challenges and solutions. Paper presented at the 2019 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM).
Ebert, C., Gallardo, G., Hernantes, J., & Serrano, N. (2016). DevOps. IEEE Software, 33(3), 94-100.
Farah, D. (2020). The modern MLOps blueprint. Retrieved from https://medium.com/slalom-data-analytics/the-modern-mlops-blueprint-c8322af69d21
Floridi, L., & Cowls, J. (2019). A unified framework of five principles for AI in society. Harvard Data Science Review, 1(1).
Garousi, V., Felderer, M., & Mäntylä, M. V. (2016). The need for multivocal literature reviews in software engineering: Complementing systematic literature reviews with grey literature. Paper presented at the 20th International Conference on Evaluation and Assessment in Software Engineering.
Github. (2020). Awesome production machine learning. Retrieved from https://github.com/EthicalML/awesome-production-machine-learning
Google Cloud. (2020). MLOps: Continuous delivery and automation pipelines in machine learning. Retrieved from https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
Haakman, M., Cruz, L., Huijgens, H., & van Deursen, A. (2020). AI lifecycle models need to be revised. An exploratory study in fintech. arXiv preprint arXiv:2010.02716.
Heck, P. (2019). Software engineering for machine learning applications. Retrieved from https://fontysblogt.nl/software-engineering-for-machine-learning-applications/
Heck, P. (2020). Testing machine learning applications. Retrieved from https://fontysblogt.nl/testing-machine-learning-applications/
Heck, P., & Schouten, G. (2021). Lessons learned from educating AI engineers. Paper accepted for the 1st International Workshop on AI Engineering (WAIN).
Hesenius, M., Schwenzfeier, N., Meyer, O., Koop, W., & Gruhn, V. (2019). Towards a software engineering process for developing data-driven applications. Paper presented at the 2019 IEEE/ACM 7th International Workshop on Realizing Artificial Intelligence Synergies in Software Engineering (RAISE).
Hulten, G. (2019). Building intelligent systems. Apress.
Institute for Ethical AI & Machine Learning. (2020). Machine learning maturity model v1.0. Retrieved from https://ethical.institute/mlmm.html
Ishikawa, F., & Yoshioka, N. (2019). How do engineers perceive difficulties in engineering of machine-learning systems? Questionnaire survey. Paper presented at the 2019 IEEE/ACM Joint 7th International Workshop on Conducting Empirical Studies in Industry (CESI) and 6th International Workshop on Software Engineering Research and Industrial Practice (SER&IP).
Jurney, R. (2017). Agile data science 2.0: Building full-stack data analytics applications with Spark. O’Reilly Media.
Kang, H., Le, M., & Tao, S. (2016). Container and microservice driven design for cloud infrastructure devops. Paper presented at the 2016 IEEE International Conference on Cloud Engineering (IC2E).
Karnowski, J., & Fadely, R. (2016). How AI careers fit into the data landscape. Retrieved from https://blog.insightdatascience.com/how-emerging-ai-roles-fit-in-the-data-landscape-d4cd922c389b
Keim, D., Kohlhammer, J., Ellis, G., & Mansmann, F. (2010). Mastering the information age: Solving problems with visual analytics. VisMaster
Kery, M. B., Radensky, M., Arya, M., John, B. E., & Myers, B. A. (2018). The story in the notebook: Exploratory data science using a literate programming tool. Paper presented at the CHI Conference on Human Factors in Computing Systems.
Kim, M., Zimmermann, T., DeLine, R., & Begel, A. (2017). Data scientists in software teams: State of the art and challenges. IEEE Transactions on Software Engineering, 44(11), 1024-1038.
Kirk, M. (2017). Thoughtful machine learning with Python: A test-driven approach. O’Reilly Media.
Koller, B. (2020). 12 Factors of reproducible Machine Learning in production. Retrieved from https://blog.maiot.io/12-factors-of-ml-in-production/
Krensky, P., den Hamer, P., Brethenoux, E., Hare, J., Idoine, C., Linden, A., Sicular, S., & Choudhary, F. (2020). Magic quadrant for data science and machine learning platforms.
Kriens, P., & Verbelen, T. (2019). Software engineering practices for machine learning. arXiv preprint arXiv:1906.10366.
Kühn, A., Joppen, R., Reinhart, F., Röltgen, D., von Enzberg, S., & Dumitrescu, R. (2018). Analytics Canvas–A Framework for the design and specification of data analytics projects. Procedia CIRP, 70, 162-167.
Lwakatare, L. E., Raj, A., Bosch, J., Olsson, H. H., & Crnkovic, I. (2019). A taxonomy of software engineering challenges for machine learning systems: An empirical investigation. Paper presented at the International Conference on Agile Software Development.
Lwakatare, L. E., Raj, A., Crnkovic, I., Bosch, J., & Olsson, H. H. (2020). Large-scale machine learning systems in real-world industrial settings: A review of challenges and solutions. Information and Software Technology, 127, 106368.
Marbán, O., Segovia, J., Menasalvas, E., & Fernández-Baizán, C. (2009). Toward data mining engineering: A software engineering approach. Information systems, 34(1), 87-107.
Marcus, G., & Davis, E. (2019). Rebooting AI: Building artificial intelligence we can trust. Vintage.
McAteer, M. (2020). Nitpicking machine learning technical debt. Retrieved from https://matthewmcateer.me/blog/machine-learning-technical-debt/
Menzies, T. (2019). The five laws of SE for AI. IEEE Software, 37(1), 81-85.
Microsoft. (2020a). What are Azure Machine Learning pipelines? Retrieved from https://docs.microsoft.com/en-us/azure/machine-learning/concept-ml-pipelines
Microsoft. (2020b). What is the Team Data Science Process? Retrieved from https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/overview
Mitchell, M., Wu, S., Zaldivar, A., Barnes, P., Vasserman, L., Hutchinson, B., Spitzer, E., Raji, I. D., & Gebru, T. (2019). Model cards for model reporting. Paper presented at the Conference on Fairness, Accountability, and Transparency.
Molnar, C. (2020). Interpretable machine learning. Lulu.Com.
Nori, H., Jenkins, S., Koch, P., & Caruana, R. (2019). Interpretml: A unified framework for machine learning interpretability. arXiv preprint arXiv:1909.09223.
Oved, D. (2018). Real-time human pose estimation in the browser with TensorFlow.js. Retrieved from https://medium.com/tensorflow/real-time-human-pose-estimation-in-the-browser-with-tensorflow-js-7dd0bc881cd5
Ozkaya, I. (2020). What is really different in engineering AI-enabled systems? IEEE Software, 37(4), 3-6.
Pinhasi, A. (2020). Deploying machine learning models to production: Inference service architecture patterns. Retrieved from https://medium.com/data-for-ai/deploying-machine-learning-models-to-production-inference-service-architecture-patterns-bc8051f70080
Provost, F., & Fawcett, T. (2013). Data science for business: What you need to know about data mining and data-analytic thinking. O’Reilly Media.
Raman, A., & Hoder, C. (2020). Building intelligent apps with cognitive APIs. O’Reilly.
Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why should I trust you?”: Explaining the predictions of any classifier. Paper presented at the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, California, USA.
Rollins, J. (2015). Why we need a methodology for data science. Retrieved from https://www.ibmbigdatahub.com/blog/why-we-need-methodology-data-science
Sato, D., Wider, A., & Windheuser, C. (2019). Continuous delivery for machine learning: Automating the end-to-end lifecycle of machine learning applications. Retrieved from https://martinfowler.com/articles/cd4ml.html
Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., & Young, M. (2014). Machine learning: The high interest credit card of technical debt. Paper presented at the SE4ML Workshop (NIPS 2014).
Serban, A., van der Blom, K., Hoos, H., & Visser, J. (2020). Adoption and effects of software engineering best practices in machine learning. Paper presented at the ESEM conference.
Sommerville, I. (2019). Artificial intelligence and systems engineering.
Sommerville, I., & Sawyer, P. (1997). Requirements engineering: A good practice guide. John Wiley & Sons, Inc.
Spiekermann, S. (2015). Ethical IT innovation: A value-based system design approach. CRC Press.
Tan, D. (2019). Coding habits for data scientists. Retrieved from https://www.thoughtworks.com/insights/blog/coding-habits-data-scientists
Thalheim, B. (2013). Entity-relationship modeling: Foundations of database technology. Springer Science & Business Media.
Valohai, SigOpt, & Tecton. (2020). Practical MLOps: How to get ready for production models.
Visengeriyeva, L., Kammer, A., Bär, I., Kniesz, A., & Plöd, M. (n.d.). Machine learning operations. Retrieved from https://ml-ops.org/
Vogelsang, A., & Borg, M. (2019). Requirements engineering for machine learning: Perspectives from data scientists. Paper presented at the IEEE 27th International Requirements Engineering Conference Workshops (REW).
Wang, D., Weisz, J. D., Muller, M., Ram, P., Geyer, W., Dugan, C., Tausczik, Y., Samulowitz, H., & Gray, A. (2019). Human-AI collaboration in data science: Exploring data scientists’ perceptions of automated AI. Proceedings of the ACM on Human-Computer Interaction, 3(CSCW), 1-24.
Washizaki, H., Uchida, H., Khomh, F., & Guéhéneuc, Y.-G. (2020). Machine learning architecture and design patterns.
Yan, E. (2019). Data science and agile: What works and what doesn’t work. Retrieved from https://towardsdatascience.com/agiledatascience-3b7ca65278a4
Zhang, J., Harman, M., Ma, L., & Liu, Y. (2020). Machine learning testing: Survey, landscapes and horizons. IEEE Transactions on Software Engineering (Early Access).
Zhang, T., Gao, C., Ma, L., Lyu, M., & Kim, M. (2019). An empirical study of common challenges in developing deep learning applications. Paper presented at the 2019 IEEE 30th International Symposium on Software Reliability Engineering (ISSRE).
Zinkevich, M. (2017). Rules of machine learning: Best practices for ML engineering. Retrieved from https://developers.google.com/machine-learning/guides/rules-of-ml
Additional Reading
Dubovikov, K. (2019). Managing data science. Packt.
Géron, A. (2019). Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, tools, and techniques to build intelligent systems. O’Reilly Media.
Github. (2020a). Awesome MLOps. Retrieved from https://github.com/visenger/awesome-mlops
Kaestner, C. (2020). Software engineering for AI/ML: An annotated bibliography. Retrieved from https://github.com/ckaestne/seaibib
Lakshmanan, V., Robinson, S., & Munn, M. (2020). Machine learning design patterns. O’Reilly Media.
Ng, A. (2019). Machine learning yearning: Technical strategy for AI engineers in the era of deep learning. Retrieved from https://www.deeplearning.ai/machine-learning-yearning/
Patruno, L. (2020). The ultimate guide to deploying machine learning models. Retrieved from https://mlinproduction.com/deploying-machine-learning-models/
Smith, J. (2018). Machine learning systems: Designs that scale. Manning Publications Co.
Sweenor, D., Hillion, S., Rope, D., Kannabiran, D., Hill, T., & O’Connell, M. (2020). MLOps: Operationalizing data science. O’Reilly.
Taifi, M. (2020). Clean machine learning code. Leanpub.

 Vind ik leuk
Vind ik leuk
Over Petra Heck
Petra werkt sinds 2002 in de ICT, begonnen als software engineer, daarna kwaliteitsconsultant en nu docent Software Engineering. Petra is gepromoveerd (kwaliteit van agile requirements) en doet sinds februari 2019 onderzoek naar Applied Data Science en Software Engineering. Petra geeft regelmatig lezingen en is auteur van diverse publicaties waaronder het boek "Succes met de requirements".