

In a previous post I argued that engineering machine learning applications is different from traditional (rule-based) software engineering. I identified eight challenges for engineering machine learning applications:
- Data requirements engineering including data visualizations
- ML components are more difficult to handle as distinct modules
- Design of the ML component through algorithm selection and tuning
- Break up the ML development in increments
- Data and model management for the current and future projects
- Find ML models that can be reused for your application
- Validation of ML applications in absence of a specification to test against
- Explainability of ML models is needed for debugging
In this post I focus on the last two challenges and give an overview of the theory, tools, frameworks and best practices I have found until now around the testing (and debugging) of machine learning applications. I will start by giving an overview of the specificities of testing machine learning applications.
Engineering Machine Learning Applications
In traditional software engineering, the software engineer starts by collecting the requirements from the stakeholders. Then the engineer translates these requirements in rules or algorithms to implement in the software. When the software operates, the rules or algorithms are executed exactly as programmed by the engineer to provide answers to the end user (see Figure 1). A bug in the answers means the engineer made a mistake in programming the rules. The software engineering community has a lot of testing tools, techniques and frameworks that help in validating the programmed rules before the software goes live.

Fig 1. Classical programming [16]
To create a machine learning application, the engineer has to follow a two-phase approach. First, the engineer has to collect data that provides good examples of the behaviour the stakeholders would like to see. This behaviour is specified by input data combined with correct answers (i.e. labelled data). Then the engineer needs to “train” (i.e. select the right algorithm and tune its parameters) a machine learning model to learn from those examples the rules that connect input data to answers. The first phase thus ends with a trained machine learning model. The second phase consists of building an application that allows the end user to input new data and get an answer from the trained machine learning model (i.e. perform inference). A bug in the answer can mean either a mistake in the example data, or a mistake in the trained machine learning model, or a mistake in the programmed application code.
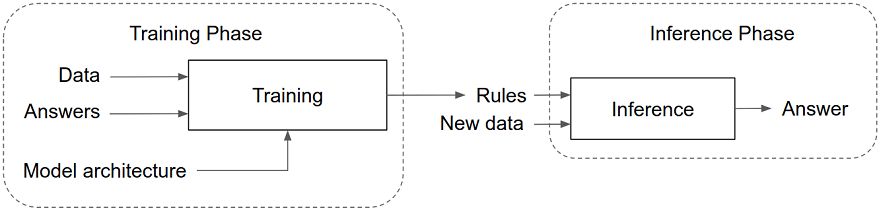
Fig 2. Machine learning [16]
Challenges for Testing Machine Learning Applications
According to Zhang et al. [1], the way machine learning applications are built leads to several challenges for testing them:
- You need to test both data, code, the learning program and the frameworks (e.g. TensorFlow) that support your ML development.
- Traditional test adequacy criteria such as test coverage do not apply.
- Each time training data is updated the behaviour of your ML model may change.
- Creating a test oracle (i.e. data labelling) is time-consuming and labour-intensive because domain-specific knowledge is required.
- Due to the difficulty in obtaining reliable oracles, ML testing tends to yield more false positives in the reported bugs.
Zhang et al. describe 128 papers on ML testing (how they address those challenges), but is written from a research perspective. They state that “compared to traditional testing, the existing tool support in ML testing is relatively immature. There remains plenty of space for tool-support improvement for ML testing.” In my experience new posts, tools and ideas on this topic come out every day. I devote the remainder of this post to solutions to the above challenges that are available for the ML engineer today.
Solutions for Testing Machine Learning Applications
Zhang et al. [1] provide a nice overview of the components involved in ML model building, see Fig 3. When testing ML applications, developers try to find bugs in every component (data, learning program, framework).
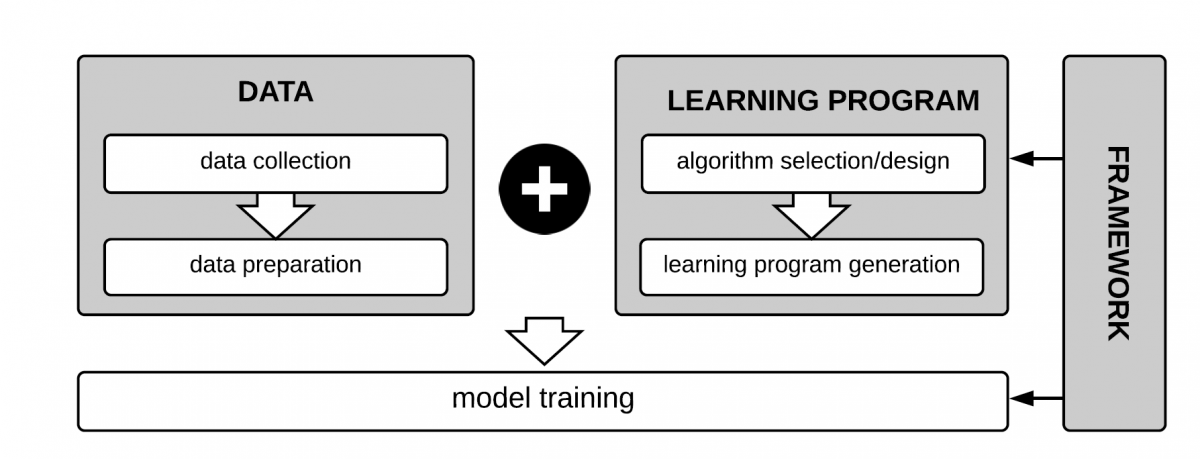
Fig 3. Components involved in ML model building [1]
I organize the solutions according to the component they are testing. Next to that I present practical solutions pertaining to the test process and test organisation.
Test the data
According to Zhang et al [1] bug detection in data should check problems such as “whether the data is sufficient for training, whether the data is representative of future data, whether the data contains a lot of noise such as biased labels, whether there is skew between training data and test data, and whether there is data poisoning or adversary information that may affect the model’s performance”. For data testing it is largely up-to the developer to come up with good test cases. However, I found some pointers to engineering tools they could use.
1) Type and Schema Checking
“To ensure data quality and integrity, data scientists often check their format, type and schema to see whether individual fields are well defined. Some even write scripts to verify a metadata and whether table columns are well defined. This type checking can help the data scientists to ensure that data are clean and not corrupted with malformed inputs” [2].
2) Check Implicit Constraints
“Data scientists often check implicit constraints, like assertions in software testing. Such constraints are not about single data points, but rather how the subgroups of data relate to other subgroups.” [2]. The example they give is to check whether the percentage of customers that downloads the licence from location A matches the percentage of licences that is activated from location A.
3) Data Linter
Hynes et al. [3] propose a tool inspired by code linters to automatically inspect ML datasets. Development teams could write their own data linters for standardized data quality checks.
4) Frameworks by big players
Breck et al. [4] describe a data validation system that is included in Google’s TFX end-to-end machine learning platform (see also TFDV). It lets the developer define a data schema that is used to check data properties and to generate synthetic data to test the model.
Schelter et al. [5] from Amazon describe a declarative API, which enables a developer to write ‘unit tests’ for data by combining common quality constraints with user-defined validation code.
Ré et al. [6] from Apple developed Overton that provides the engineer with abstractions that allow them to build, maintain, and monitor their application by manipulating data files. The ML model is built automatically from the supervision data and model goals that the engineer specifies, so the engineer does not need to select the algorithm or tune its parameters manually. Inspired by relational systems, supervision (data) is managed separately from the model (schema).
5) Test input generation
Most ML applications need more (diverse) data to train the ML model then there is available. That is where test input generation comes into play. Zhang et al [1] provide a comprehensive overview of different test input generation techniques. They could be used as a basis for the developer to come up with application-specific test data generation scripts. This is also called data augmentation. For image data there exists a number of standard image data augmentation techniques.
One can generate natural input or adversarial input. Adversarial input is input data that does not belong to the normal data distribution and is useful to expose robustness or security flaws. This could be implemented in Python using the cleverhans library.
Zhang et al. [1] point out that metamorphic relations are widely studied to tackle the test oracle problem. An example is Murphy et al. [7]. They use adding a constant to numerical values, multiplying numerical values by a constant, permuting the order of the input data, reversing the order of the input data, removing a part of the input data, adding additional data. These changes to the input data should yield unchanged or certain expected changes in the predictive output.
Another way of obtaining expected predictive output is to compare different implementations of the same algorithm, e.g. in different libraries or frameworks.
Test the learning program
The learning program (i.e. the ML model) is a combination of the ML algorithm that is selected or designed and the code written by the developer to implement, configure or deploy it. According to Zhang et al. [1] the trained ML model should be tested for the following properties: correctness, overfitting degree, fairness, interpretability, robustness, security, data privacy, and efficiency. I will discuss the first 4 properties in more detail plus some general solutions when developing ML models.
1) Correctness & Overfitting
Standard validation approaches to ensure correctness of ML models and detect overfitting are cross-validation and bootstrap. Widely-adopted correctness measures are accuracy, precision, recall and AUC [1]. Zhang et al. [1] found that several papers indicate that one should be careful in choosing the performance metric and that it is essential to consider their meaning when adopting them. We know that for datasets that have unbalanced label categories accuracy (% predicted correct) is not a valid evaluation metric and AUC is preferred.
Papers by Zhang et al. [9] and Ma et al. [8] provide an academic treatment of two solutions to reduce overfitting. I did not find any practical implementation, but I include them here to give an idea that new methods are being worked on.
The work of Zhang et al. [9] indicates that Perturbed Model Validation is a better way of detecting overfitting than cross-validation.
Ma et al. [8] propose MODE (Automated Neural Network Model Debugging) that uses resampling of the training data to relieve the overfitting problem. MODE first performs the model state differential analysis with the correctly classified inputs and misclassified inputs for the label and generates the benign and faulty heat maps for a selected hidden layer. Based on the generated benign and faulty heat maps for the selected layer, MODE performs various differential analyses (according to the bug type) to generate the differential heat map, which highlights the target features for retraining. The differential heat map is used as guidance to select existing or new inputs (generated by GANs or collected from the real world) to form a new training dataset, which is then used to retrain the model and fix the bug.
2) Fairness
A fairness bug occurs when differences in model performance are measured for different groups or individuals. Zhang et al. [1] summarize the work on fairness for ML including a few test generation techniques for fairness testing. Examples are Themis, Aequitas and FairTest which have been implemented in Python and are available on GitHub with ample instructions.
IBM initiated a comprehensive open source toolkit for fairness, called AI Fairness 360 Open Source Toolkit. The AI Fairness 360 Python package includes a comprehensive set of metrics for datasets and models to test for biases, explanations for these metrics, and algorithms to mitigate bias in datasets and models.
Sculley et al. [10] describe a simple solution to test for so-called prediction bias: “In a system that is working as intended, it should usually be the case that the distribution of predicted labels is equal to the distribution of observed labels. This is by no means a comprehensive test, as it can be met by a null model that simply predicts average values of label occurrences without regard to the input features. However, it is a surprisingly useful diagnostic, and changes in metrics such as this are often indicative of an issue that requires attention. For example, this method can help to detect cases in which the world behavior suddenly changes, making training distributions drawn from historical data no longer reflective of current reality. Slicing prediction bias by various dimensions isolate issues quickly, and can also be used for automated alerting.” [10]
3) Interpretability
Machine learning interpretability refers to the degree to which an observer can understand the cause of a decision made by an ML system [1]. On the one hand interpretability is one of the properties to test against because it might be a user requirement (“the user needs to know what the rationale behind the decision for medical treatment A or B is”). On the other hand we must keep in mind that interpretable models are easier to test for correctness because they provide more means to find root causes of incorrect answers. So one could also argue that interpretability should be taken into account for all models.
The online book “Interpretable Machine Learning” by Cristoph Molnar is a comprehensive resource of interpretation methods with examples in R. There are also Python libraries for these methods, e.g. for LIME and SHAP. The Python SHAP library is also used in this tutorial from Kaggle.
The Institute for Ethical AI & ML published the explainability toolkit XAI, available for Python on GitHub.
H2O developed a Machine Learning Interpretability module to include explainable AI in their automatic machine learning platform (commercially available). As they state “Being able to explain and trust the outcome of an AI-driven business decision is now a crucial aspect of the data science journey.”. Interpretability is key for the success of such commercial platforms, specifically for regulated environments such as banking, insurance, and healthcare.
4) Code habits
Code to train ML models is typically written in Python in Jupyter notebooks. According to David Tan this code is “full of (i) side effects (e.g. print statements, pretty-printed dataframes, data visualisations) and (ii) glue code without any abstraction, modularisation and automated tests.”. In his article he shares techniques for identifying bad code habits that add to complexity as well as habits that can help partition complexity.
5) Other testing solutions for the learning program
The Tensorflow machine learning cookbook by Nick McClure [15] describes how to develop unit tests for Tensorflow models using the built-in test functions of Tensorflow. McClure notes that Python also has a testing library called Nose.
Sagemaker Debugger is a component of the AWS Sagemaker platform: “Amazon SageMaker Debugger provides full visibility into the training of machine learning models by monitoring, recording, and analyzing the tensor data that captures the state of a machine learning training job at each instance in its lifecycle. It provides a rich set of alerts when detecting errors for the steps of a machine learning training trial, and the ability to perform interactive explorations.”
Sculley et al. [10] do not see many starting points for testing ML systems yet. They mention that: “In systems that are used to take actions in the real world, it can be useful to set and enforce action limits as a sanity check.”
Zhang et al. [1] describe mutation testing as a promising direction for coping with the absence of coverage criteria. One of its implementations for Deep Neural Networks is DeepMutation, available on GitHub for Python.
Test Process and Organization
There are a number of solutions I found that do not pertain to one particular component to be tested, but rather to the way the testing process is organized. I will introduce them in this section.
In this respect I would also like to mention the A4Q AI and Software Testing Foundation certification that provides an elaborate syllabus on testing AI applications and the use of AI in testing. The certification is related to the ISTQB Certified Tester which is the global standard in Software Testing. It is good to see that organizations also aim to standardize the language and activities in testing of ML applications (main focus of the A4Q certification).
1) Testing workflow
Zhang et al. [1] give a nice overview of the testing workflow for ML applications, see Figure 4. There needs to be an online testing process because unseen data can change the behaviour of the ML applications in unexpected ways (this is due to the separate training and inference environments, see Figure 2).
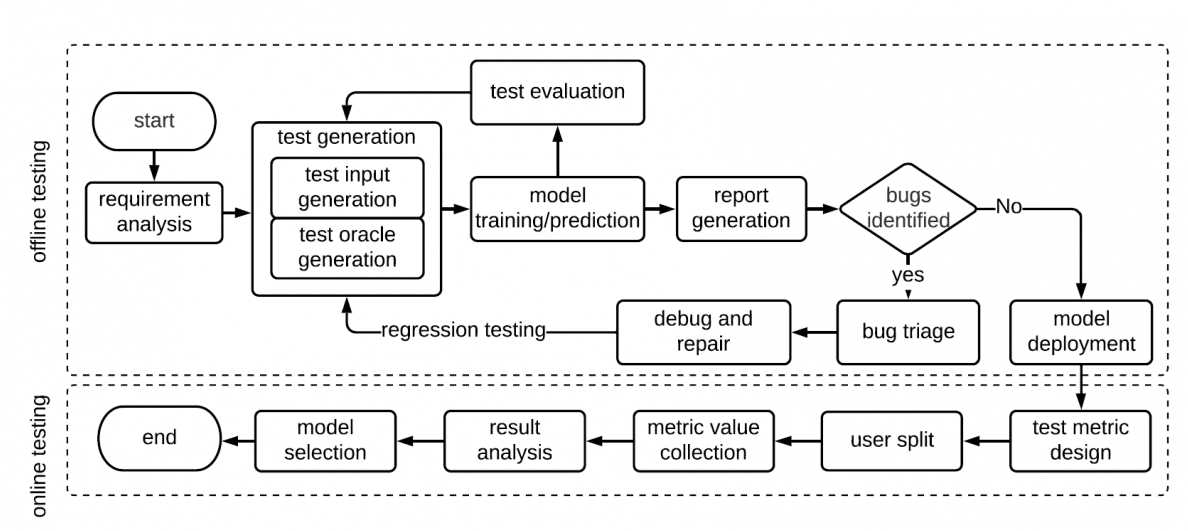
Fig 4. ML testing workflow [1]
Since the paper by Zhang et al. comes from Facebook, the workflow explicitly includes A/B testing (“user split” where they provide groups of users with different models to test which one works better). This might not be relevant for all environments, but it is still a good idea to come up with production level metrics for monitoring your ML models. I have seen organizations where they automatically fall back to previous versions of models and worst-case even to a rule-based approach when certain failures occur or certain metrics reach a threshold.
2) Evolutionary prototyping
The book by Partridge [11] states that the way to deal with the fact that the behaviour of the ML system cannot be specified upfront is to develop the system according to what we now call evolutionary prototyping or agile datascience. Partridge captured this in what he calls the RUDE cycle:
- Run the current version of the system;
- Understand the behavior observed;
- Debug the algorithm to eliminate undesired and introduce desired behavior;
- Edit the program to introduce the modifications decided upon.
The challenge is to come up with increments small enough to test and debug in a meaningful way. One example can be found in the picture below.
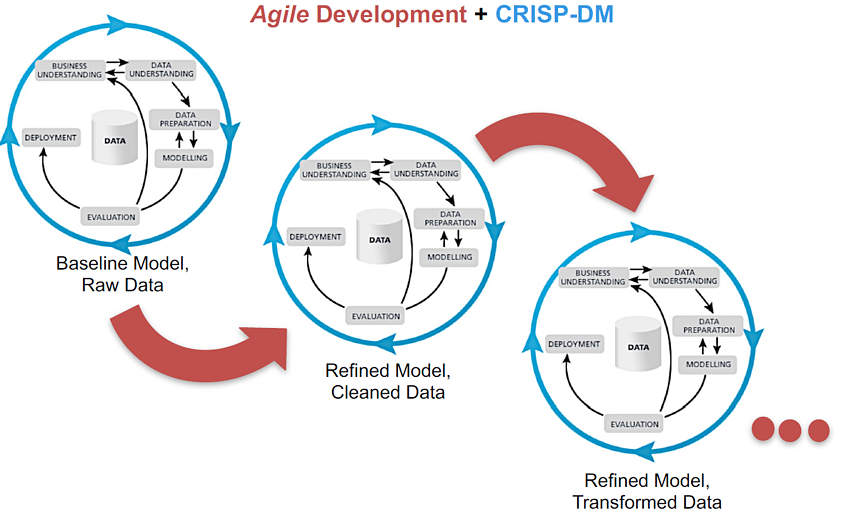
Fig 5. Taken from https://www.elderresearch.com/blog/benefits-of-agile-data-science
3) Test-driven ML
Test-driven development is an approach to software development where you write tests before you start writing code. The books by Kirk [12] and Bozonier [13] provide an implementation of this approach to ML applications with examples in Python. They describe many different ways to test ML code.
4) Testing rules
Breck et al. [14] present a set of actionable tests, and offer a scoring system to measure how ready for production a given machine learning system is. This scoring system is used at Google, but could also be adapted for other environments. It gives an idea of the types of things we need to check before an ML system can go live.
Another set of rules is given by Zinkevich from Google, of which the following apply to the testing process:
- Rule #5: Test the infrastructure independently from the machine learning
- Rule #23: You are not a typical end user.
- Rule #14: Starting with an interpretable model makes debugging easier.
5) Version control
With ML applications a bug can be in the dataset, the glue code, the ML algorithm or the parameter settings of the algorithm, see also Figure 3. In case you need to trace bugs, it might help a lot if you can easily revert to previous versions of each component. There exist specialized version control tools like DVC and MLFlow for use in ML applications. They help to run controlled experiments with parameter settings and input data to implement a testing workflow similar to the one shown in Figure 4.
6) Monitoring tools
As the testing workflow in Figure 4 also shows, online monitoring of ML systems is of utmost importance. We need to detect any unexpected behaviour due to changes in input data. According to Gade there are 4 classes of monitoring:
- Feature Monitoring: This is to ensure that features are stable over time, certain data invariants are upheld, any checks w.r.t privacy can be made as well as continuous insight into statistics like feature correlations.
- Model Ops Monitoring: Staleness, regressions in serving latency, throughput, RAM usage, etc.
- Model Performance Monitoring: Regressions in prediction quality at inference time.
- Model Bias Monitoring: Unknown introductions of bias both direct and latent.
More and more tools come to the market that make this possible and good ML platforms should have built-in options for this (e.g. Azure or Sagemaker). Use those built-in options or build your own dashboards and monitoring tools when not using standard ML platforms.
7) Multidisciplinary teams
I would like to end this list of testing solutions by reiterating one of the most important lessons from testing in software engineering: testing is a multidisciplinary activity that should involve all stakeholders. Most importantly it cannot be done by the developers alone!
For testing ML applications this is even more so true because of the test oracle problem. To determine if a given output is correct we often need the opinion of a domain expert. Imagine the detection of cancer cells on X-ray images. How can a developer tell if the ML model detected the right cells?
The challenge is to find a way of communicating ML model output to domain experts such that they can validate the output in an easy manner. You should build your ML applications keeping this in mind, adding extra features for model monitoring and validation targeted at domain experts. This usually involves dashboards with proper interactive data visualizations.
References
[1] Zhang, J. M., Harman, M., Ma, L., & Liu, Y. (2020). Machine learning testing: Survey, landscapes and horizons. IEEE Transactions on Software Engineering.
[2] M. Kim, T. Zimmermann, R. DeLine and A. Begel (2018). Data Scientists in Software Teams: State of the Art and Challenges. IEEE Transactions on Software Engineering, vol. 44, no. 11, pp. 1024-1038.
[3] Hynes, N., Sculley, D., & Terry, M. (2017). The data linter: Lightweight, automated sanity checking for ml data sets. In NIPS MLSys Workshop.
[4] Breck, E., Polyzotis, N., Roy, S., Whang, S. E., & Zinkevich, M. (2019, April). Data validation for machine learning. In Conference on Systems and Machine Learning (SysML).
[5] Sebastian Schelter, Dustin Lange, Philipp Schmidt, Meltem Celikel, Felix Biessmann, and Andreas Grafberger (2018). Automating large-scale data quality verification. Proc. VLDB Endow. 11, 12 (August 2018), 1781–1794.
[6] Ré, C., Niu, F., Gudipati, P., & Srisuwananukorn, C. (2019). Overton: A Data System for Monitoring and Improving Machine-Learned Products. ArXiv, abs/1909.05372.
[7] Murphy, C., Kaiser, G. E., & Hu, L. (2008). Properties of machine learning applications for use in metamorphic testing.
[8] Shiqing Ma, Yingqi Liu, Wen-Chuan Lee, Xiangyu Zhang, and Ananth Grama (2018). MODE: automated neural network model debugging via state differential analysis and input selection. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2018). Association for Computing Machinery, New York, NY, USA, 175–186.
[9] Zhang, J., Barr, E.T., Guedj, B., Harman, M., & Shawe-Taylor, J. (2019). Perturbed Model Validation: A New Framework to Validate Model Relevance. ArXiv, abs/1905.10201.
[10] Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary V. & Young, M. (2014). Machine learning: The high interest credit card of technical debt.
[11] Partridge, D. (1992). Engineering Artificial Intelligence Software, Intellect Books.
[12] Kirk, M. (2017) Thoughtful Machine Learning with Python, O’Reilly.
[13] Bozonier, J. (2015) Test-Driven Machine Learning, Packt Publishing.
[14] Breck, E., Cai, S., Nielsen, E., Salib, M., & Sculley, D. (2016). What’s your ML Test Score? A rubric for ML production systems.
[15] McClure, N. (2017). TensorFlow Machine Learning Cookbook, Packt Publishing.
[16] https://www.manning.com/books/deep-learning-with-javascript
![]()
Dit onderzoek is medegefinancierd door Regieorgaan SIA onderdeel van de Nederlandse Organisatie voor Wetenschappelijk Onderzoek (NWO)

 Vind ik leuk
Vind ik leuk
Over Petra Heck
Petra werkt sinds 2002 in de ICT, begonnen als software engineer, daarna kwaliteitsconsultant en nu docent Software Engineering. Petra is gepromoveerd (kwaliteit van agile requirements) en doet sinds februari 2019 onderzoek naar Applied Data Science en Software Engineering. Petra geeft regelmatig lezingen en is auteur van diverse publicaties waaronder het boek "Succes met de requirements".