

In recent years more and more software applications contain machine learning components (Ozkaya, 2020). This means that software engineers should learn how to build these type of systems (Menzies, 2019). Instead of just code, also datasets and machine learning models become first class citizens in the development process.
The past two years I have conducted an extensive literature and tool review to answer the question: “What should software engineers learn about building production-ready machine learning systems?”. This is because at Fontys University of Applied Sciences we are educating this type of software engineers. At the same time, I saw that in many companies a similar question arises because the software engineers working there have not been educated with machine learning knowledge. So, they need to update their skills on the job. I also saw many variations of this question.
I focus on software engineers, because this is my own background. Others have a background in data analytics, data science or mathematics and also need to contribute to building production-ready machine learning systems. The following picture gives a nice overview of the different disciplines involved:

Fig 1. Disciplines involved in building intelligent systems, adapted from (Karnowski & Fadely, 2016)
During my research I noted that because the discipline of building production-ready machine learning systems is so new, it is not so easy to get the terminology straight. People write about it from different perspectives and backgrounds and have not yet found each other to join forces. At the same time the field is moving fast and far from mature.
My focus on material that is ready to be used with our bachelor level students (applied software engineers, profession-oriented education), helped me to consolidate everything I have found into a body of knowledge for building production-ready machine learning (ML) systems. In this post I will first define the discipline and introduce the terminology. In a later post I will address the challenges from my earlier post by listing all the solutions I have found during my research.
AI Engineering or MLOps?
The first International Workshop on Artificial Intelligence (AI) Engineering (WAIN21) defines AI engineering using the following picture, taken from Lwakatare et al. (2020):
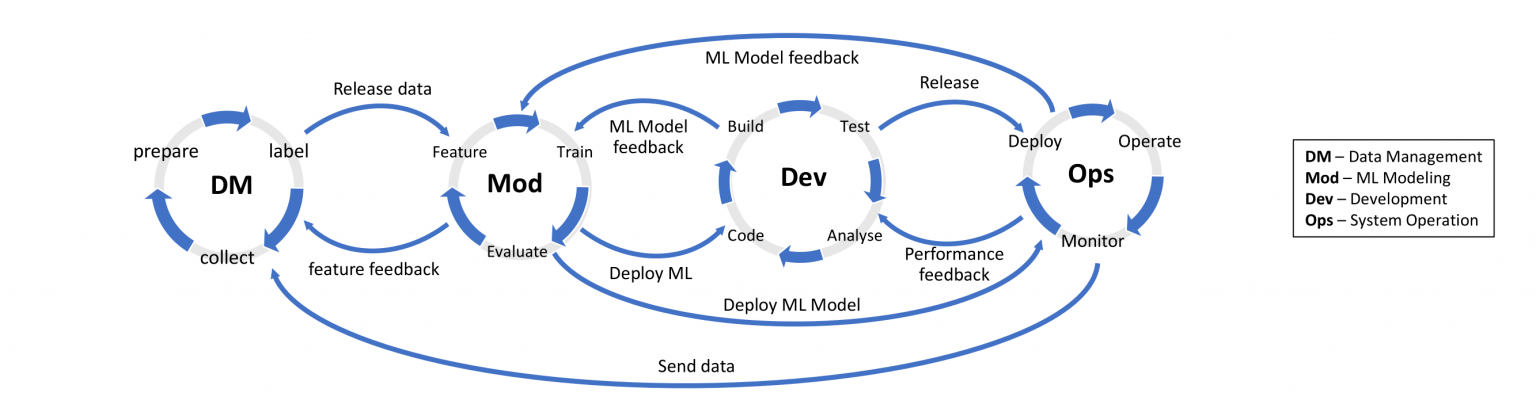 Fig 2. AI engineering lifecycle, taken from Lwakatare et al.(2020)
Fig 2. AI engineering lifecycle, taken from Lwakatare et al.(2020)
This picture is highly similar to the pictures that are used to define MLOps. For example:
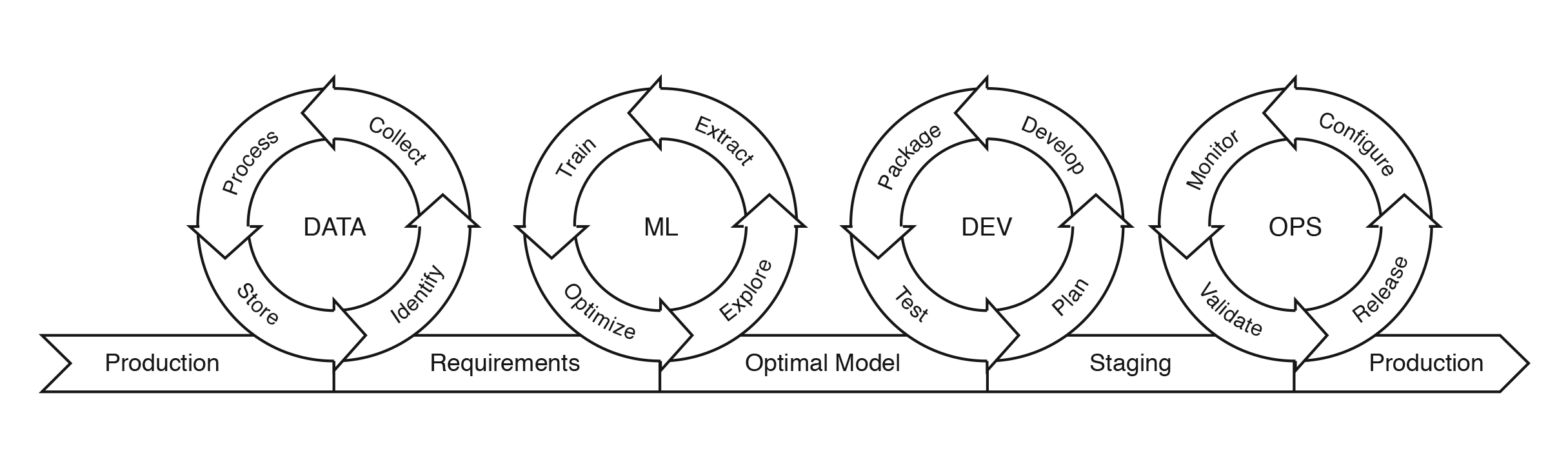
Fig 3. MLOps lifecycle, adapted from (Farah, 2020)
In my opinion AI Engineering and MLOps are two different names for the same: building production-ready machine learning systems. From what I saw the term AI Engineering came from the academics as a subfield or extension of software engineering whereas the term MLOps came from the industry as a subfield or extension of DevOps (Ebert et al., 2016).
Another confusion I encountered is between AI and ML. In my opinion, most of the AI-enabled systems are in fact ML-enabled systems. You can also see in the above two pictures that they talk about ML, not AI in general. There are multiple definitions of AI, but in general it refers to “autonomous machine intelligence” or “systems that can sense, reason, act and adapt”. Whereas ML is a subset of this, defined as “algorithms to build AI”. And, as you can see in the picture below, ML includes deep learning as a special type of algorithms to build AI. What I see is that people tend to use the term AI because it sounds more sexy than the technical term ML.
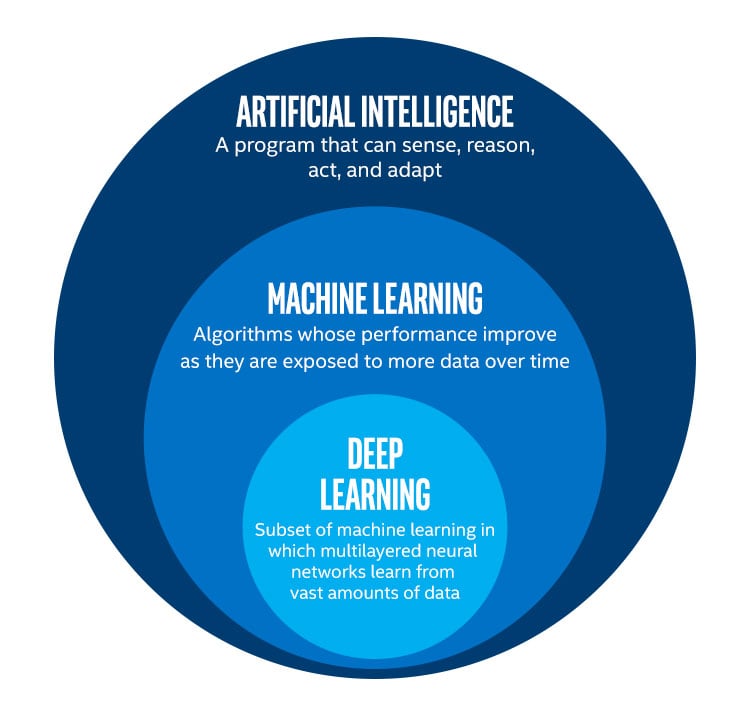 Fig 4. AI versus ML versus Deep Learning, taken from Intel
Fig 4. AI versus ML versus Deep Learning, taken from Intel
Since our students are being educated as software engineers for industry, I prefer to use the term MLOps for my body of knowledge. Our students are familiar with DevOps from their software engineering background, and we build upon this by extending it with frameworks and tools for MLOps. As you can see in Figure 3, the last two circles are in fact the regular DevOps circles, but now they need to work with data engineers and data scientists to extend the DevOps principles to the entire lifecycle of ML systems (adding data and models). So, another view on MLOps is building production-ready ML systems with a multidisciplinary team and integrated approach, as depicted in the following figure:
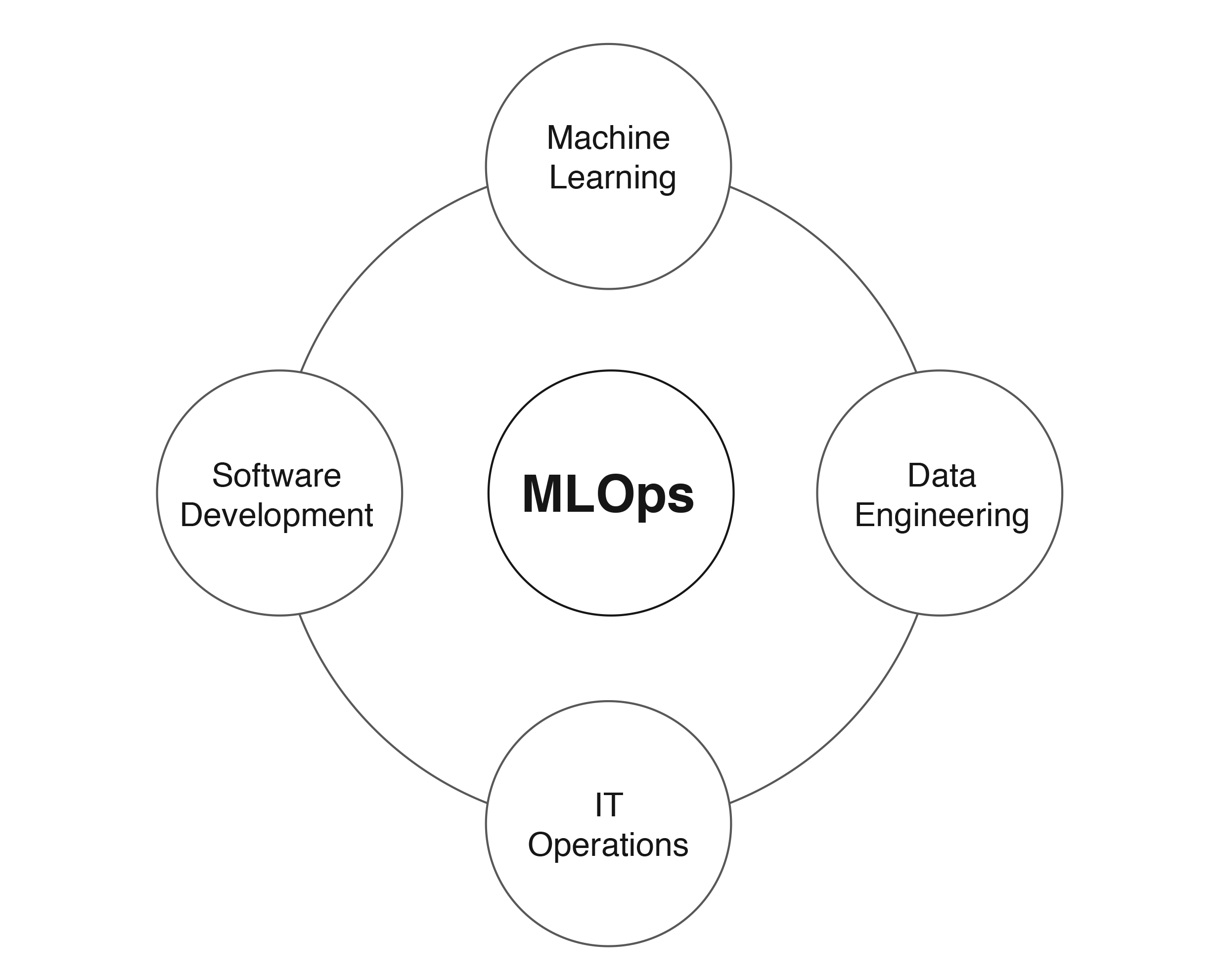
Fig 5. MLOps needs a multi-disciplinary team
What is MLOps?
Visengeriyeva et al. (n.d.) define MLOps as “an end-to-end machine learning development process to design, build and manage reproducible, testable, and evolvable ML-powered software”. From a software engineering perspective MLOps could be seen as the extension of DevOps to include machine learning models and data sets as first-class citizens.
Note that since MLOps is an emerging field you will find different names being used for the same, such as “Continuous Delivery for Machine Learning (CD4ML)” (Sato et al., 2019) or “Software Engineering for Machine Learning (SE4ML)” or “Machine Learning Engineering” (Burkov, 2020). All these describe a set of best practices for building production-ready machine learning systems.
A summary of these best practices has been given by the MLOps manifesto. Production-ready ML systems should:
- be developed with a collaborative team across the full ML lifecycle from data to deployment;
- deliver reproducible and traceable results;
- be continuously monitored and improved.
Google Cloud (2020) defines three maturity levels for MLOps and introduces the concept of Continuous Training (as an extension of Continuous Integration and Continuous Delivery from DevOps). Continuous Training deals with automatically retraining and serving ML models in the production environment whenever new data comes in, without or with little human intervention. For the highest MLOps maturity level, Google describes the MLOps setup depicted below:
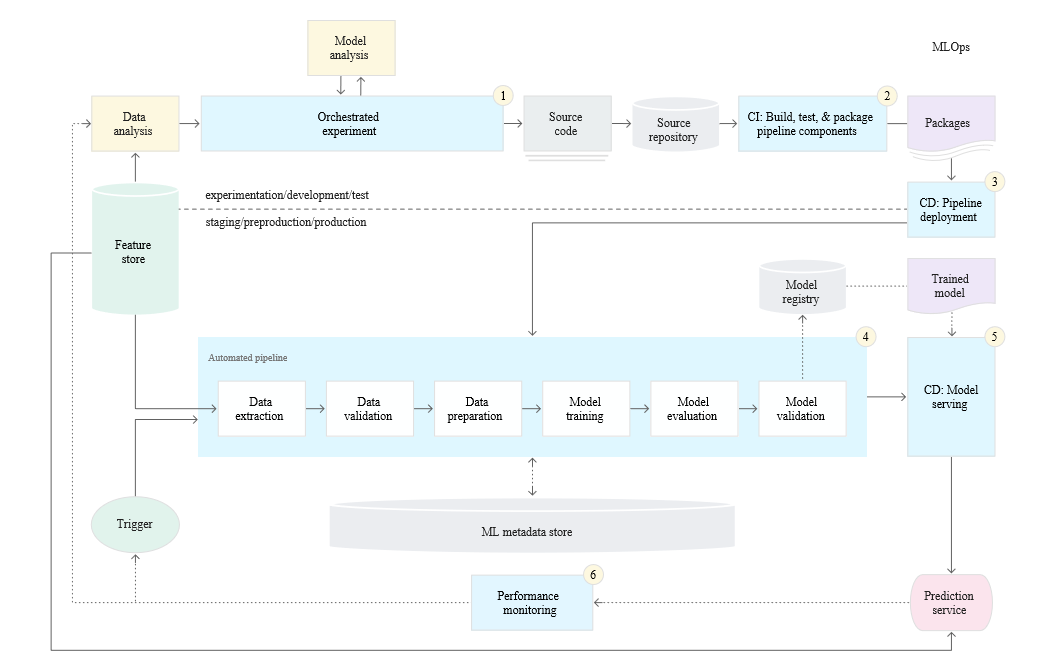
Fig 6. MLOps Level 2: CI/CD and automated ML pipeline, taken from Google Cloud (2020)
Best Practices in MLOps
During my literature survey, I have extracted best practices from the works of several authors (Akkiraju et al., 2020; Breuel, 2020; Google Cloud, 2020; Koller, 2020; Valohai et al., 2020; Visengeriyeva et al., n.d.; Zinkevich, 2017). To give an idea of the type of best practices mentioned, I include a synthesised overview (thanks to Luís Cruz from TU Delft J) here:
- Automate data validation – offline and online.
- Version control everything: data, code, models, parameters, and environment.
- Keep track of experiments via automation. Record information about each experiment to help with data and artefacts lineage, reproducibility, and comparisons.
- Design the right metrics to track and set the threshold of their acceptable values, usually empirically, and often by comparing with previous models or benchmarks.
- Use pipelines and automation.
- Implement automated testing. Test code and models continuously throughout the lifecycle and update test sets accordingly.
- Implement CI/CD. Every training pipeline needs to produce a deployable artefact, not “just” a model.
- Continuous Training (CT). Automate the ML production pipelines to retrain the models with new data.
- Continuous Monitoring (CM). Actively monitor the quality of your model in production.
- Work in hybrid teams, including data science, data engineering, ML engineering, and DevOps.
- Write readable code.
- Document data, model, code, and feature dependencies.
Another source of best practices to keep track of is the ongoing research of the SE4ML group at Leiden University. They also identified specific best practices around ethical machine learning (“trustworthy machine learning”).
Tool Support for MLOps
The best practices in MLOps (the same as for DevOps) are only achievable with considerable tool support. Visengeriyeva et al. (n.d.) already indicate that for this tool support you have options ranging from a commercial machine learning platform (see Gartner’s Magic Quadrant for Data Science and Machine Learning Platforms by Krensky et al. (2021)) to an in-house solution composed of multiple open-source libraries (see the “Awesome production ML” list by EthicalML (2020)).
Interesting to see is the vast amount of tool categories on the latter list. This indicates everything that needs to be taken care of in building production-ready machine learning systems:
| Explaining predictions & models | Privacy preserving ML | Model & data versioning |
| Model training orchestration | Model serving and monitoring | Neural architecture search |
| Reproducible notebooks | Visualization frameworks | Industry-strength NLP |
| Data pipelines & ETL | Data labelling | Data storage |
| Functions as a service | Computation distribution | Model serialization |
| Optimized calculation frameworks | Data stream processing | Outlier and anomaly detection |
| Feature engineering | Feature stores | Adversarial robustness |
Table 1. Categories of open-source tool support for production ML, adapted from (EthicalML, 2020)
Selecting the right platform or tools and optimizing it for your MLOps environment is an activity by its own. The MLOps solution is bound to change with new tools, new version or new usage scenarios. Thus it is paramount to dedicate resources to this and to incorporate continuous improvement of the tool support as well.
Useful Resources
- Github. (2020a). Awesome MLOps. Retrieved from https://github.com/visenger/awesome-mlops
- Kaestner, C. (2020). Software engineering for AI/ML: An annotated bibliography. Retrieved from https://github.com/ckaestne/seaibib
- Ng, A. (2019). Machine learning yearning: Technical strategy for AI engineers in the era of deep learning. Retrieved from https://www.deeplearning.ai/machine-learning-yearning/
- Patruno, L. (2020). The ultimate guide to deploying machine learning models. Retrieved from https://mlinproduction.com/deploying-machine-learning-models/
- Smith, J. (2018). Machine learning systems: Designs that scale. Manning Publications Co.
- Sweenor, D., Hillion, S., Rope, D., Kannabiran, D., Hill, T., & O’Connell, M. (2020). MLOps: Operationalizing data science. O’Reilly.
References
- Akkiraju, R., Sinha, V., Xu, A., Mahmud, J., Gundecha, P., Liu, Z., Liu, X., & Schumacher, J. (2020). Characterizing machine learning processes: A maturity framework. Paper presented at the International Conference on Business Process Management.
- Breuel, C. (2020, Jan 3, 2020). MLOps: Machine learning as an engineering discipline. Retrieved from https://towardsdatascience.com/ml-ops-machine-learning-as-an-engineering-discipline-b86ca4874a3f
- Burkov, A. (2020). Machine learning engineering. True Positive Inc.
- Ebert, C., Gallardo, G., Hernantes, J., & Serrano, N. (2016). DevOps. IEEE Software, 33(3), 94-100.
- EthicalML. (2020). Awesome production machine learning. Retrieved from https://github.com/EthicalML/awesome-production-machine-learning
- Farah, D. (2020). The modern MLOps blueprint. Retrieved from https://medium.com/slalom-data-analytics/the-modern-mlops-blueprint-c8322af69d21
- Google Cloud. (2020). MLOps: Continuous delivery and automation pipelines in machine learning. Retrieved from https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- Karnowski, J., & Fadely, R. (2016). How AI careers fit into the data landscape. Retrieved from https://blog.insightdatascience.com/how-emerging-ai-roles-fit-in-the-data-landscape-d4cd922c389b
- Koller, B. (2020). 12 Factors of reproducible Machine Learning in production. Retrieved from https://blog.maiot.io/12-factors-of-ml-in-production/
- Krensky, P., Idoine, C., Brethenoux, E., den Hamer, Choudhary, F., Jaffri, A., & Vashisth, S. (2021). Magic quadrant for data science and machine learning platforms.
- Lwakatare, L. E., Crnkovic, I., & Bosch, J. (2020). DevOps for AI – Challenges in Development of AI-enabled Applications. 2020 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), pp. 1-6, doi: 10.23919/SoftCOM50211.2020.9238323.
- Menzies, T. (2019). The five laws of SE for AI. IEEE Software, 37(1), 81-85.
- Ozkaya, I. (2020). What is really different in engineering AI-enabled systems? IEEE Software, 37(4), 3-6.
- Sato, D., Wider, A., & Windheuser, C. (2019). Continuous delivery for machine learning: Automating the end-to-end lifecycle of machine learning applications. Retrieved from https://martinfowler.com/articles/cd4ml.html
- Valohai, SigOpt, & Tecton. (2020). Practical MLOps: How to get ready for production models.
- Visengeriyeva, L., Kammer, A., Bär, I., Kniesz, A., & Plöd, M. (n.d.). Machine learning operations. Retrieved from https://ml-ops.org/
- Zinkevich, M. (2017). Rules of machine learning: Best practices for ML engineering. Retrieved from https://developers.google.com/machine-learning/guides/rules-of-ml

 Vind ik leuk
Vind ik leuk
Over Petra Heck
Petra werkt sinds 2002 in de ICT, begonnen als software engineer, daarna kwaliteitsconsultant en nu docent Software Engineering. Petra is gepromoveerd (kwaliteit van agile requirements) en doet sinds februari 2019 onderzoek naar Applied Data Science en Software Engineering. Petra geeft regelmatig lezingen en is auteur van diverse publicaties waaronder het boek "Succes met de requirements".