

Both Software Engineering and Machine Learning have become recognized disciplines. In this article I analyse the combination of the two: engineering of machine learning applications. In my opinion this relatively new discipline needs further work on methods, tools, frameworks and tutorials.
The Wikipedia page on Software Engineering defines software engineering (SE) as “the application of engineering to the development of software in a systematic method”. This page shows links to several sub disciplines, tools, frameworks, best practices, paradigms, methodologies. I am a lecturer in software engineering at the ICT department of Fontys University (Fontys ICT, bachelor level). The past years I saw more and more software engineering students involved in graduation assignments applying machine learning in their software products. To support this trend, Fontys ICT developed a study program for ICT students that want to dive into applied machine learning.
Application of machine learning is within reach for every software developer because of the availability of computing power (cloud systems), open source tools/libraries and even pretrained models or APIs. I see a strong parallel with what happened in software development. Only now machine learning applications are widespread in production-like environments we realize that we miss some tools/methodologies to engineer them following a systematic method. This systematic method is exactly what we need to educate our ICT students on.
I believe the systematic way of working for machine learning applications is at certain points different from traditional (rule-based) software engineering. The question I set out to investigate is “How does software engineering change when we develop machine learning applications”?. This question is not an easy to answer and turns out to be a rather new, with few publications. This article collects what I have found until now. If you are interested in updates feel free to send me a DM through LinkedIn or p.heck (at) fontys.nl.
Machine Learning versus Rule-Based
Machine learning (ML) can be defined as: “algorithms and statistical models that computer systems use in order to perform a specific task effectively without using explicit instructions, relying on patterns and inference instead”. The part “without using explicit instructions” is exactly what contrasts it with traditional software. In traditional programming the software developer discovers (business) rules and programs them explicitly in a method or algorithm. This is called rule-based programming.
In machine learning applications the software developer selects and sets up algorithms that learn from data (i.e. creates an ML model). By feeding examples to the software (input and correct output), the algorithm would learn the patterns in the data and could then infer the most probable output for any unseen inputs[1]. Nowadays a wide variety of proven self-learning algorithms is available for software developers, such that they can focus on preparation of training data and tuning of the algorithm’s hyperparameters (not building the algorithm).
Development Process
Different software engineering life cycles have been proposed over the years. Nowadays most organizations seem to follow an agile approach but even then the basic cycle remains: 1) define requirements, 2) design the software solution, 3) implement the solution, 4) test against requirements. For each of these steps a lot of support is available to execute them in a structured way (management tools, drawing tools, IDEs, books, best practices, etc.).
For educating our ICT students in machine learning we use the Foundational Methodology for Data Science published by IBM as a whitepaper. This process is based on CRISP-DM, a cross-industry standard for Data Mining that was published around 2000 and has a detailed user guide available. Both methodologies follow the same basic cycle: 1) define analytical approach (i.e. frame the business problem in terms of machine learning techniques and data requirements); 2) collect, merge, wrangle, clean and transform the data (I call that “data design”); 3) build the machine learning model 4) evaluate the model outcome.
If you are developing a software application that includes machine learning algorithms you somehow need to combine the two process models for software engineering and machine learning. This is visualized in Figure 1 (note that not all feedback loops have been drawn). Combining these two process models makes clear that two different streams (software and ML model) need to be developed in parallel, starting from a common understanding and ending with an integrated software solution. This of course requires regular synchronization between the streams, if they are not executed by the same person. A solution for this lies in the adoption of agile practices for machine learning, such that both streams follow the same sprint rhythm, preferably in the same sprint team. In that way, each sprint delivers and reviews an integrated MVP (Minimal Viable Product).
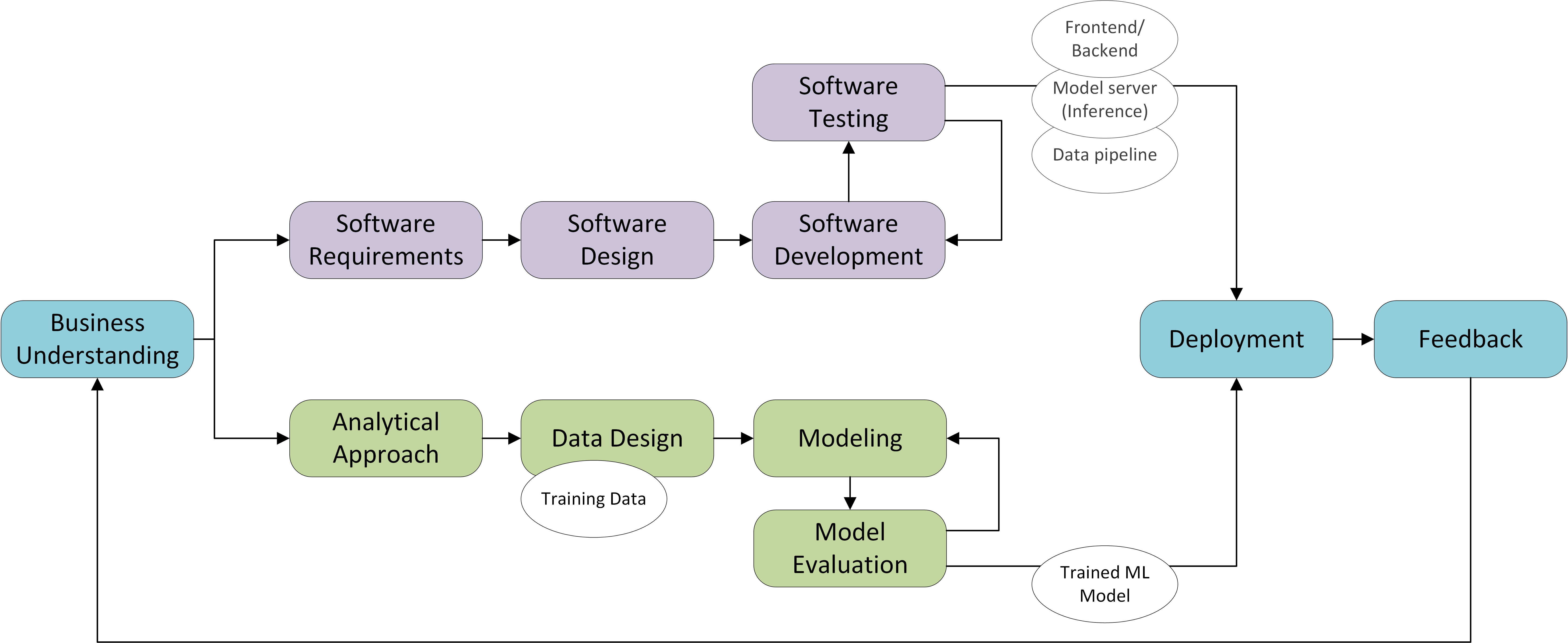
Figure 1. Combining Software Engineering and Machine Learning processes
Challenges for Engineering ML Applications
In this paragraph I detail challenges faced in engineering machine learning applications (for references see below). I focus on those challenges that stem from the difference with traditional rule-based software engineering.
Challenge 1 – Data requirements engineering including data visualizations
According to Maciaszek et al. (2005) software engineering is about modeling. The requirements model is a relatively informal model that captures user requirements and describes the system in terms of its business value. In traditional rule-based software engineering we would specify requirements in terms of “rules”. These rules would captured the behavior of the system in, for example, use cases or user stories. The use cases would need to be validated with the stakeholders before system design and implementation.
We cannot take that same approach for machine learning applications, because we want the system to learn the rules from the data (in particular the training set). So, we need to shift our focus from requirement engineering to data engineering. We need to feed the machine learning application an appropriate dataset with input-output pairs and we need to understand the data to be able to interpret the validity of the predictions[1]. We need to elicit data requirements instead of software requirements.
For rule-based software engineering we would use requirements documents or user stories to communicate with the stakeholders and get their approval before we start design and build. For machine learning applications we need another way to communicate with the stakeholders about the data. This is typically done through exploratory data visualizations, but this requires specific skills and tools very different from traditional requirements engineering.
Challenge 2 – ML components are more difficult to handle as distinct modules
A key strategy for coping with complex systems is to modularize them. In other words, to break the total system down into a collection of more or less independent and simpler subsystems (Partridge, 1992). Saleema Amershi et al. (2019) state the following about this: “Maintaining strict module boundaries between machine learned models is difficult for two reasons. First, models are not easily extensible. For example, one cannot (yet) take an NLP model of English and add a separate NLP model for ordering pizza and expect them to work properly together. Similarly, one cannot take that same model for pizza and pair it with an equivalent NLP model for French and have it work. The models would have to be developed and trained together. Second, models interact in non-obvious ways. In large-scale systems with more than a single model, each model’s results will affect one another’s training and tuning processes. In fact, one model’s effectiveness will change as a result of the other model, even if their code is kept separated. Thus, even if separate teams built each model, they would have to collaborate closely in order to properly train or maintain the full system. This phenomenon (also referred to as component entanglement) can lead to non-monotonic error propagation, meaning that improvements in one part of the system might decrease the overall system quality because the rest of the system is not tuned to the latest improvements.”
Challenge 3 – Design of the ML component through algorithm selection and tuning
For the design of one single ML component, one does not code the complete algorithm or all the rules. Instead, we need to select the proper ML algorithm (and dataset) for the problem at hand. The ML algorithm is treated as a black box that needs to be tuned (through so-called hyper-parameters) to the problem at hand. Deep learning algorithms also require the design of an architecture for the underlying neural network. This leaves the designer with a huge solution space that requires a feasible strategy to select and tune the right algorithm. This is a very different way of working from the software specification that is used in traditional software engineering (e.g. UML models, model-based development, test-driven development). Developments such as AutoML suggest that algorithm selection and hyper-parameter tuning might be obsolete in the near future. But for now, I do not see this widely used in practice.
Challenge 4 – Break up the ML development in increments
Already in 1992, Partridge identifies that AI systems tend to be built incrementally (following an evolutionary paradigm) captured in what he calls the RUDE cycle:
1. Run the current version of the system;
2. Understand the behavior observed;
3. Debug the algorithm to eliminate undesired and introduce desired behavior;
4. Edit the program to introduce the modifications decided upon.
This fits with what we nowadays know as the agile way of working and supports my claim that agile development is mandatory for machine learning applications. We can simply not specify everything on beforehand and get approval before we start design and build. Data preparation and hyper-parameter tuning are intertwined and need to be approached in small iterations such that intermediate results can be shown to stakeholders to be validated. The input from domain experts is necessary for the developer to decide on the next step for model improvement, the same as user stories are reprioritized each sprint in traditional agile development.
Challenge 5 – Data and model management for the current and future projects
The agile approach to model improvement magnifies the need for version control of ML models and datasets. At each point in time we need to be able to reproduce results from earlier sprints. We might need to revert to an earlier version of the model or need to retest different model version with different dataset versions. This is also important for dataset reuse in other projects (Saleema Amershi et al., 2019). Saleema et al. (2019) found that most developers within Microsoft feel the need for integration data management tools in their ML framework.
Challenge 6 – Find ML models that can be reused for your application
According to Sommerville (2011) reuse is one of the fundamental principles for software systems. This also holds for ML applications. However, since ML algorithms behave as a black box (without a functional specification of its behavior) it is far more difficult to assess which black box can be reused for your current problem. Furthermore, reuse of ML algorithms can be done on several levels: 1) you can use an API with no influence on the model behind it (e.g. Microsoft or Google Vision API); 2) you can use a pretrained model as-is; 3) you can use an existing model and (partly) retrain it yourself; 4) you can use an existing library and build your model from scratch. All this again requires a highly experimental approach and a good deal of creativity to come up with ideas.
What we see with our students is that the amount of available tools, libraries and models, is huge (all open-source) and that they are not disclosed in a structured way. And new ones become available every day. Often it takes more effort to search for a model to be reused than to develop a new one yourself.
Challenge 7 – Validation of ML applications in absence of a specification to test against
The only way to tell if the outcome of an ML model is correct is to verify this with domain experts. Even then we usually cannot say “this outcome is 100% correct” but more something like “this outcome makes sense” (e.g. client X should be denied a loan and customer Y should be given a loan according to the model). The testing of machine learning applications is an evaluation done with domain experts where we can never be sure that we tested all edge cases (because we do not know the white-box specification of the ML model). This also means that evaluation should continue in production: a human should be in the loop to verify that the model outcomes still make sense (even more so because input data may change over time). To have domain experts validate model outcomes we often need the same advanced visualization techniques as we need for data requirements validation (see Requirements paragraph).
The presentations at the 2019 Software Engineering for Machine Learning Applications (SEMLA) international symposium of Dietterich and Zhang (full paper available) contain a more academic treatment of the correctness and testing of ML applications.
Challenge 8 – Explainability of ML models is needed for debugging
Problems often occur when a domain expert or the developer finds the outcome of the ML model to be “incorrect” or “not making sense”. We cannot go into a regular debugging process because to the developer the ML model is a black box. Basically, we need to know what characteristics of the input caused the model to predict the output. Then, we need to figure out if we need to tune the input data or the model itself to improve the output. This is a hard task that again requires a lot of experimentation. Currently a lot of work is being done on improving the explainability of machine learning models. This is from the perspective of a person being affected by a decision made based on a model outcome. But these type of tools could also help developers in debugging the models. Most work is still academic and published in scientific papers but we already see some practical examples on Explainable AI (XAI): a Kaggle course on ML explainability or an industry-wide XAI framework.
Conclusion
We can point out several differences between rule-based software engineering and machine learning based software engineering. These differences result in challenges for a systematic method. Some challenges are already being addressed by industry and academics, whereas others still need to be explored in production-like environments. My ongoing research aims at collecting, for example, practical tools, frameworks and methodologies for the systematic approach to engineering of machine learning applications. This toolbox can be used to educate Fontys ICT students but also practitioners with a software engineering background that start developing machine learning applications.![]()
Dit onderzoek is medegefinancierd door Regieorgaan SIA onderdeel van de Nederlandse Organisatie voor Wetenschappelijk Onderzoek (NWO)
References and further reading
- Engineering Artificial Intelligence Software (Derek Partridge, 1992) This is an old one from the period that expert systems started to be developed, but still rather applicable to current machine learning applications; updated editions have been published until 2013. See also the book Artificial Intelligence & Software Engineering edited by Derek Partridge in 1991.
- Engineering AI Systems for Mission-Practical Capabilities (SEI, online) The SEI is addressing a variety of challenges of engineering AI-enabled systems. Such challenges include scalability, representation, AI architectures, verification and validation for AI assurance, and interpretability.
- Software 2.0 (Andrej Karpathy, 2017) “Neural networks are not just another classifier, they represent the beginning of a fundamental shift in how we write software. They are Software 2.0. … In the 2.0 stack, the programming is done by accumulating, massaging and cleaning datasets.”
- SEMLA Symposium (Polytechnique Montreal, online) The Software Engineering for Machine Learning Applications (SEMLA) international symposium, started in 2018, aims at bringing together leading researchers and practitioners in software engineering and machine learning to reflect on and discuss the challenges and implications of engineering complex data-intensive software systems. See also the summary of the 2018 conference.
- Machine Teaching A New Paradigm for Building Machine Learning Systems (Synced, 2017) The field of machine learning has spent most of its effort to develop and improve learning algorithms. If the given data are plentiful, this approach can play an important role. When the demand to solve such kinds of problems increases, the access to teachers who are responsible to build corresponding solutions will be constrained. To meet this demand, the authors suggest advancing the discipline of machine teaching.
- What machine learning means for software development (Ben Lorica and Mike Loukides, 2018) “Software development doesn’t disappear; developers have to think of themselves in much different terms. How do you build a system that solves a general problem, then teach that system to solve a specific task?”
- Software Engineering for Machine Learning: A Case Study (Saleema Amershi et al., 2019) “In addition, we have identified three aspects of the AI domain that make it fundamentally different from prior software application domains: 1) discovering, managing, and versioning the data needed for machine learning applications is much more complex and difficult than other types of software engineering, 2) model customization and model reuse require very different skills than are typically found in software teams, and 3) AI components are more difficult to handle as distinct modules than traditional software components — models may be “entangled” in complex ways and experience non-monotonic error behavior.”
- Software Engineering Challenges of Deep Learning (Anders Arpteg et al., 2018) “Compared to other areas such as software engineering or database technologies, it is clear that DL is still rather immature and in need of further work to facilitate development of high-quality systems. The challenges identified in this paper can be used to guide future research by the software engineering and DL communities.”
- What is the Role of an AI Software Engineer in a Data Science Team? (Marlon Rodrigues, 2018) “The AI Engineer is responsible for bringing a Software Engineering culture into the Data Science process. That is a massive task and involves things like: Build Infrastructure as Code, Continuous Integration and Versioning Control, Tests, API Development, Development of Pilots and MVP Applications”
- A framework for evaluating the analytic maturity of an organization (Robert L. Grossman, 2018) “… it is generally recognized as much more important that some software development methodology be used versus which particular one is chosen. This point of view is not yet common when developing analytic models. In this article, we have identified six key process areas in analytics and distinguished between five analytic maturity levels based upon the maturity of these processes.”
- AI needs a new developer stack (Krishna Gade, 2019) Describes the machine learning workflow and tries to answer the question “What would an ideal Developer Toolkit look like for an AI engineer?”
- Towards a software engineering process for developing data-driven applications (Marc Hesenius et al., 2019) Describes an approach called EDDA (Engineering Data-Driven Applications) similar to my Figure 1 above.
- Practical Software Engineering. A Case Study Approach (Leszek A. Maciaszek, Bruc Lee Liong, Stephen Bills, 2005) Description of the software engineering process, modelling, tools, and project management.
- Software engineering (Ian Sommerville, 2011) “Nevertheless, there are software engineering fundamentals that apply to all types of software system:
- They should be developed using a managed and understood development process.
- Software should behave as expected, without failures and should be available for use when it is required.
- Requirements Management. You have to know what different customers and users of the system expect from it and you have to manage their expectations so that a useful system can be delivered within budget and to schedule.
- You should make as effective use as possible of existing resources. This means that, where appropriate, you should reuse software that has already been developed rather than write new software.”
[1] note: I assume supervised machine learning throughout this article.

 Vind ik leuk
Vind ik leuk
Over Petra Heck
Petra werkt sinds 2002 in de ICT, begonnen als software engineer, daarna kwaliteitsconsultant en nu docent Software Engineering. Petra is gepromoveerd (kwaliteit van agile requirements) en doet sinds februari 2019 onderzoek naar Applied Data Science en Software Engineering. Petra geeft regelmatig lezingen en is auteur van diverse publicaties waaronder het boek "Succes met de requirements".