

More and more organizations are building production-ready machine learning systems following the MLOps paradigm. In my recent publication on data engineering for machine learning systems, I argue that AI-based systems cannot exist without data. However, in that mapping study I did not find many publications on how to do proper data engineering for AI-based systems. In this post I summarize those publications that I found, tying them to the overarching framework of DataOps. We also see this shift of attention from MLOps to DataOps in the organizations we work with at Fontys ICT. To achieve real business value with AI, the data infrastructure needs to be in order first. This post defines data engineering and DataOps, and adds to that a list of “tools” that can be used for (data) engineering trustworthy AI-based systems. The post ends with a special section on data engineering for LLM-based systems.
Data Engineering
In 2021, Andrew Ng coined the term “data-centric AI” (DCAI) for “the discipline of systematically engineering the data used to build an AI system”, i.e., AI data engineering. Reis and Housley [36] define data engineering as “the development, implementation, and maintenance, of systems and processes that take in raw data and produce high-quality, consistent information that supports downstream use cases, such as analysis and machine learning. Data engineering is the intersection of security, data management, DataOps, data architecture, orchestration and software engineering.” Figure 1 shows the data engineering life cycle.
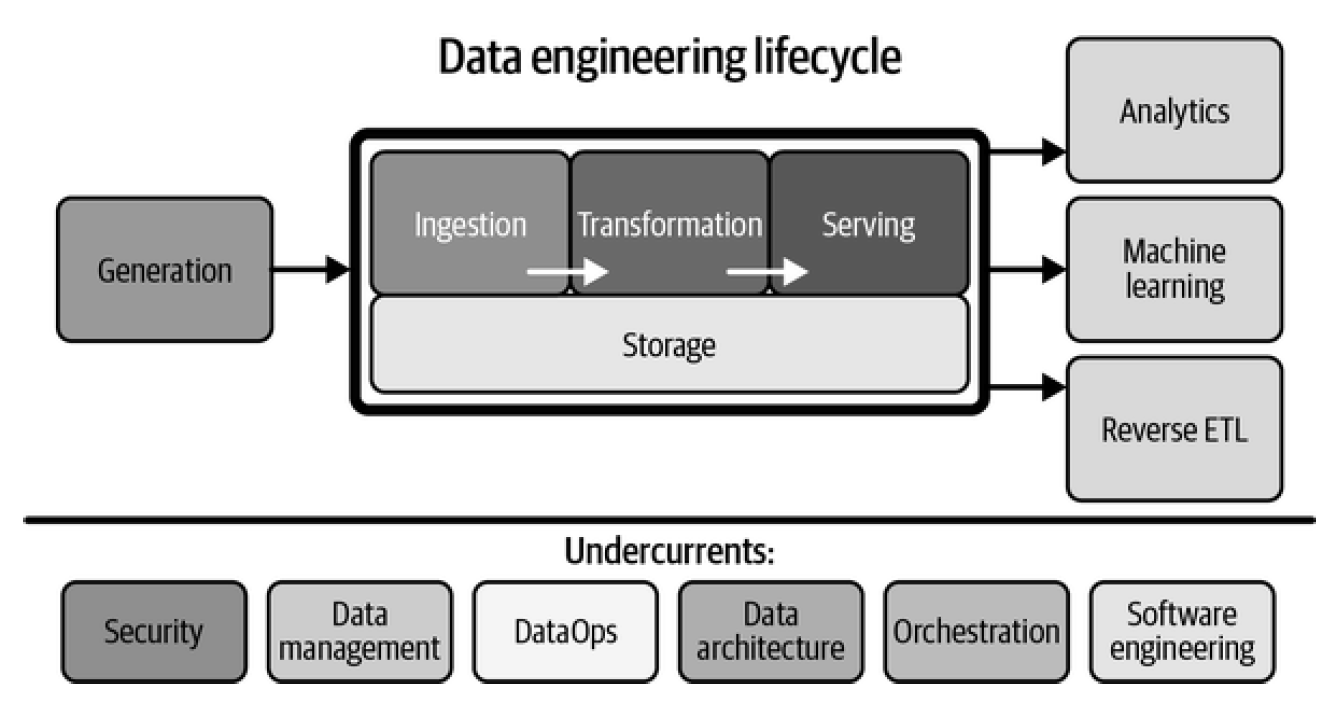
Fig 1: data engineering lifecycle (Reis and Housley, 2022)
From Figure 1 it can be seen that AI or Machine Learning (ML) is just one of the downstream use cases of a data engineering lifecycle, and that software engineering is an important undercurrent. This contrasts the AI engineering lifecycle that I depicted in my earlier blogpost on MLOps, where data and DevOps are sequential phases. Jarrahi et al. (2023) also see that “DCAI magnifies the role of data throughout the AI life cycle and stretches its lifespan beyond the so-called ‘preprocessing step’ in model-centric AI.”
A solution could be to extend the AI engineering life cycle with undercurrents such as “data architecture” and “DataOps”, analogue to Figure 1. These are data-related activities that are not just relevant for one single AI engineering project, but for the entire organization, or for all projects being executed, or for all AI systems being maintained.
Data Engineering Tools
In my literature review on data engineering for machine learning systems I discuss 7 technical solutions, 9 architectures and 9 case studies. From a practical point of view the following are most interesting:
- Gröger (2021) calls for a data ecosystem for industrial enterprises, see Figure 2. Gröger suggests to use an enterprise data catalog that provides comprehensive metadata management across all data lakes and other data sources to enable self-service use of data.
- Warnett and Zdun (2022) list architectural design decisions (ADDs) for the machine learning workflow from a gray literature study.
- Kreuzberger et al. (2023) depict an “end-to-end MLOps architecture and workflow with functional components and roles”. The workflow contains a separate data engineering zone and data(Ops) engineer is a separate role.
- Raj et al. (2020) describe eight DataOps use cases at Ericsson and derived a five stage DataOps evolution from them. For each stage they define requirements, i.e. best practices.
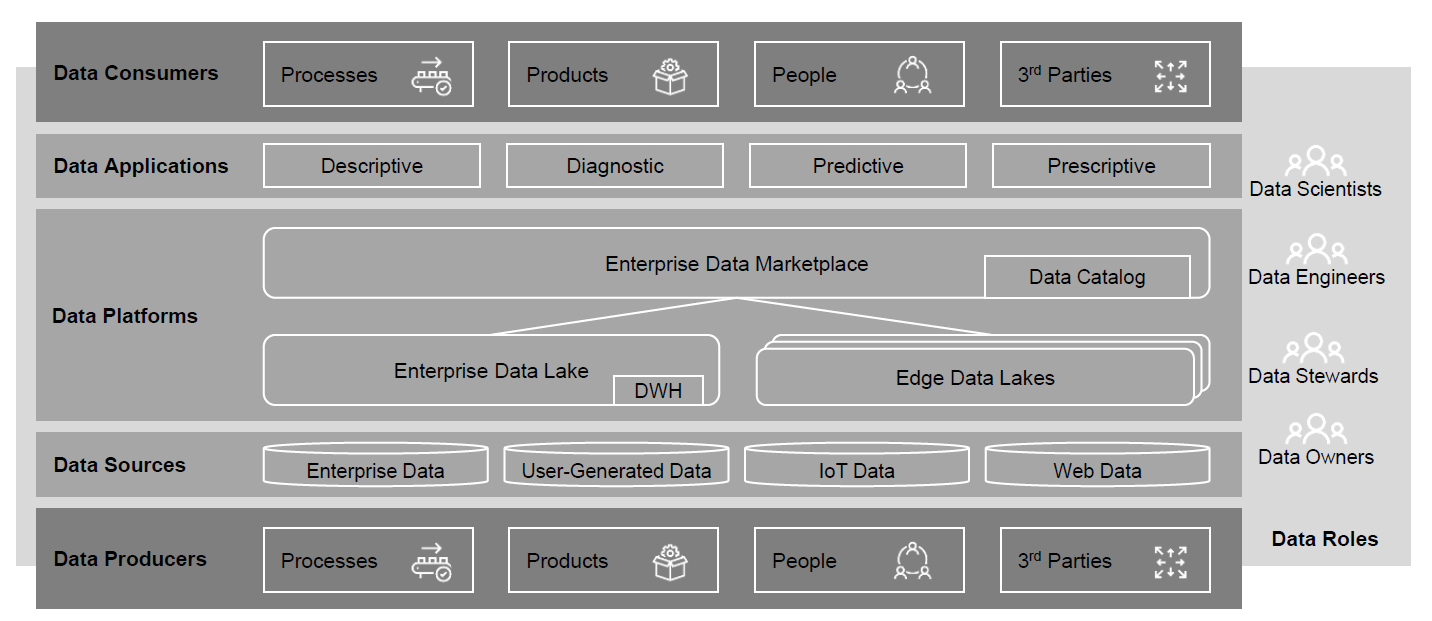
Fig 2: a data ecosystem for industrial enterprises (Gröger, 2021)
Next to those papers describing relevant solutions for data engineering for AI-based systems, I also encountered some other useful links, see also the Related Work section:
- How to do data engineering for Big Data? In my mapping study I specifically focused on AI-based systems, but broadening the scope to Big Data systems in general may yield more solutions for data engineering.
- Open source tooling for data engineering, lakeFS provides a yearly overview.
- The evolution of the data space solutions such as Gaia-X, FIWARE and the International Data Space (IDS).
- Tools and solutions for synthetic data
Our study on data engineering for AI-based systems made us realize that data needs to be a first class citizen in the project or organization. This means that data engineering is a separate stream within every project, next to software engineering and ML engineering. It also means that the architecture of an AI-based system consists of a software architecture, an ML architecture and a data architecture. We also see this development in the organizations we work with at Fontys ICT: vacancies for data engineers and data architects.
Data Quality Solutions
In our first literature review on data engineering we found some interesting links to data quality, although we did not explicitly include this in the search query. That is why we conducted a second literature review on data quality for AI-enabled systems. We found 11 papers on data quality engineering, of which 6 are new. From a practical point of view the following are most interesting:
- Breck et al. (2019) introduce TensorFlow Data Validation (part of TensorFlow Extended)
- Foidl et al. (2022) collected a catalogue of 36 “data smells” in a multi-vocal literature review and implemented tool support to detect these data smells.
- Jariwala et al. (2022) demonstrate the use of the IBM Data Quality for AI Toolkit to check training data in a machine learning setting.
Next to those papers describing relevant solutions for data engineering for AI-based systems, I also encountered some other useful links:
- Documenting datasets through, e.g., Datasheets (Gebru et al., 2021) or other data-focused documentation tools. This is a practice that is not wide-spread yet, but could help maintain high-quality datasets.
- Various data validation tools from earlier work: e.g., Great Expectations, IBM AI Fairness 360.
Our extended study on data engineering and data quality for AI-based systems made us realize that actually data quality is the foundation on which we build trustworthy AI systems, see Figure 3.
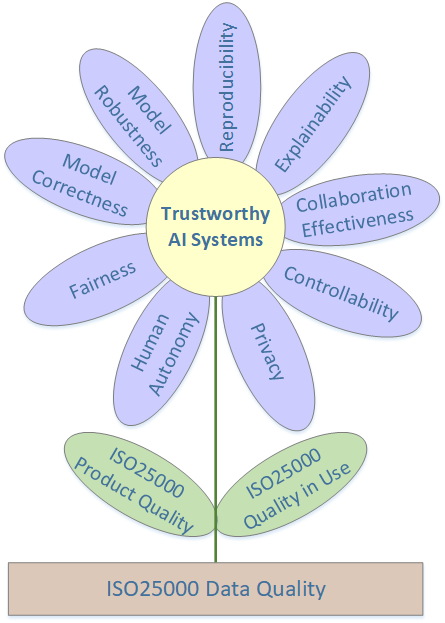
Fig 3: a quality model for trustworthy AI-based systems
DataOps
During our literature reviews we ran into the concept of DataOps. We feel that the DataOps “way of thinking” can be a practical way to professionalize an organization’s data engineering, the same as MLOps did for ML engineering. DataOps is “an approach that accelerates the delivery of high quality results by automation and orchestration of data life cycle stages” (Munappy et al., 2020). It applies agile software engineering, DevOps and Lean Manufacturing to data products. The DataOps manifesto translates this to 18 principles for a DataOps approach. According to Reis and Housley (2022) DataOps has three core technical requirements: automation, monitoring and observability, and incident response. However, they end by stating “the general practices we describe for DataOps are aspirational, and we suggest companies try to adopt them to the fullest extent possible”. This lack of maturity in data engineering was also noticed by Munappy et al. (2020) in their case study with a large mobile telecommunication organization.
Based on their case study, Munappy et al. (2020), provide an evolution model towards DataOps, for processes and infrastructure. This evolution model helps companies to identify the current stage, and a path to move to the next stage. The evolution model consists of 5 stages, each with their own technical requirements:
- Ad-hoc data analysis: manual data collection and analysis;
- Semi–automated data analysis: using data pipelines and a centralized data storage;
- Agile data science: CI/CD for data pipelines (DevOps tooling) + data visualization;
- Continuous testing and monitoring: advanced monitoring systems + automated quality checks for data pipelines;
- DataOps: full automation and orchestration of data pipelines, including artifact management (data versioning and metadata catalogue).
In one of our projects we have experimented with the design and implementation of a DataOps architecture (stage 3), using Mage.AI as a workflow engine to manage, monitor and serve data pipelines. Mage.AI and alternatives like Dagster, Prefect and Airflow belong to a “new generation of automation and data management tools” (Reis and Housley, 2022). These platforms offer easy orchestration and modular setup of (data) pipelines, which make them useful from stage 2, and in our experience a prerequisite for the higher stages of DataOps maturity.
Data Engineering for LLM-based Systems
With the advent of foundation models and generative AI, especially the recent explosion in Large Language Models (LLMs), we see our students and companies around us build a whole new type of AI-enabled systems: LLM-based systems or LLM systems in short. The most well-known example of an LLM system is the chatbot ChatGPT, but you can also build your own LLM systems. In my previous post on LLMOps, I analyze the quality characteristics of LLM systems and discuss the challenges for engineering LLM systems. I also present the solutions I have found until now to address the quality characteristics and the challenges. Since we are now talking about DataOps for AI-based systems, I would like to rediscuss the lessons learned from the perspective of data engineering for this specific type of AI-based system.
In terms of data engineering, LLMs typically work with large amounts of unstructured text data, requiring specific data pipelines and tooling tailored to that type of data. In a Retrieval Augmented Generation (RAG) system, this unstructured text data needs to be stored for easy retrieval. The current way of working is to chunk the text/documents and embed those chunks in vectors, to store them in a vector database. A more complicated architecture (graphRAG) includes a graph database to also store relationships between the chunks/documents. The good news is that the earlier mentioned data pipeline orchestration tools like Mage.AI and Dagster can also support LLMs/text-based data pipelines. We are currently experimenting with Dagster in one of our own LLM-based projects.
For LLM-based systems the real challenge lies in the automated validation of data pipelines, a necessary prerequisite for moving towards higher maturity levels of DataOps:
- How to determine that the correct document chunks have been retrieved to answer a certain question?
- How to deal with the non-deterministic nature of LLM answers? Ask the same question twice and receive different answers each time.
- How to determine if the answer is correct, given the question?
- How to monitor the quality of the input documents?
- How to deal with updates to the LLM? How to regression test question/answer pairs?
- How to ensure LLM observability?
- How to check non-functional requirements such as privacy, security and fairness?
We are currently working on a research project where we try to answer these questions and more, all related to the testing/validation of LLM systems, including the internal data pipelines. There are some frameworks for testing LLMs, but we do not see standardization yet. Our goal is to develop a reference architecture for such a validation framework. That reference architecture should serve as a blueprint to implement DataOps (as well as DevOps and MLOps) for LLM-based systems.
Conclusion
In this post we have introduced data engineering and DataOps as fundamental approaches for building AI-based systems. We have listed some practical data engineering tools that we have found until now. We have also discussed the peculiarities of DataOps for LLM-based systems.
This post summarizes the current state-of-the-art in DataOps. It points to a number of open (practical) questions. Some of those we will address in future work, but we need help with this. For companies that need to transform to higher maturity levels for DataOps, the presented evolution model and the tools we mention, provide a useful starting point. But also here we need your help. So please contact me if you are a researcher or practitioner working on data engineering for AI-based systems, so we can join forces, e.g., in the DEMAND project.
References
Eric Breck, Neoklis Polyzotis, Sudip Roy, Steven Whang, and Martin Zinkevich (2019). Data Validation for Machine Learning. In MLSys.
Harald Foidl, Michael Felderer, and Rudolf Ramler (2022). Data smells: categories, causes and consequences, and detection of suspicious data in AI-based systems. In Proceedings of the 1st International Conference on AI Engineering: Software Engineering for AI. 229–239.
T. Gebru, J. Morgenstern, B. Vecchione, J. W. Vaughan, H. Wallach, H. D. Iii, and K. Crawford (2021). Datasheets for datasets. Communications of the ACM, vol. 64, no. 12, pp. 86- 92.
Christoph Gröger (2021). There is no AI without data. Commun. ACM 64, 11(2021), 98–108.
Mohammad Hossein Jarrahi, Ali Memariani, and Shion Guha (2023). The Principles of Data-Centric AI. Commun. ACM 66, 8 (jul 2023), 84–92.
Ankur Jariwala, Aayushi Chaudhari, Chintan Bhatt, and Dac-Nhuong Le (2022). Data Quality for AI Tool: Exploratory Data Analysis on IBM API. International Journal of Intelligent Systems and Applications 14, 1 (2022), 42.
Dominik Kreuzberger, Niklas Kühl, and Sebastian Hirschl (2023). Machine learning operations (MLOps): Overview, definition, and architecture. IEEE Access (2023).
Aiswarya Raj Munappy, David Issa Mattos, Jan Bosch, Helena Holmström Olsson, and Anas Dakkak (2020). From ad-hoc data analytics to dataops. In Proceedings of the International Conference on Software and System Processes. 165–174.
Joe Reis and Matt Housley (2022). Fundamentals of Data Engineering. O’Reilly.
Stephen John Warnett and Uwe Zdun (2022). Architectural design decisions for the machine learning workflow. Computer 55, 3 (2022), 40–51.
Related Work
Harvinder Atwal (2019). Practical DataOps: Delivering agile data science at scale. Springer
Christopher Bergh, Gil Benghiat and Eran Strod (2023). The dataOps cookbook. DataKitchen Hqrs.
George Fraser, Guido Appenzeller and Derrick Harris (2024). Data management for enterprise LLMs. Podcast.
Eberhard Hechler, Maryela Weihrauch, and Yan Wu (2023). Data Fabric and Data Mesh for the AI Lifecycle. In Data Fabric and Data Mesh Approaches with AI: A Guide to AI-based Data Cataloging, Governance, Integration, Orchestration, and Consumption. Springer, 195–228.

 Vind ik leuk
Vind ik leuk
Over Petra Heck
Petra werkt sinds 2002 in de ICT, begonnen als software engineer, daarna kwaliteitsconsultant en nu docent Software Engineering. Petra is gepromoveerd (kwaliteit van agile requirements) en doet sinds februari 2019 onderzoek naar Applied Data Science en Software Engineering. Petra geeft regelmatig lezingen en is auteur van diverse publicaties waaronder het boek "Succes met de requirements".